如何与Databricks Delta和Spark Streaming一起构建端到端预测数据管道
在数据库试试这个笔记本
维护压缩机等资产是一项极其复杂的工作:它们被用于从小型钻井平台到深水平台的所有领域,资产分布在全球各地,每天产生tb级的数据。bob体育客户端下载这些压缩机中只要有一台出现故障,每天就会造成数百万美元的生产损失。节省时间和金钱的一个重要方法是使用机器学习来预测停机并发出维护工作单之前发生故障。
最终,您需要构建一个端到端预测数据管道,可以提供一个实时数据库来维护资产部件和传感器映射,支持处理大量遥测数据的连续应用程序,并允许您根据这些数据集预测压缩机故障。
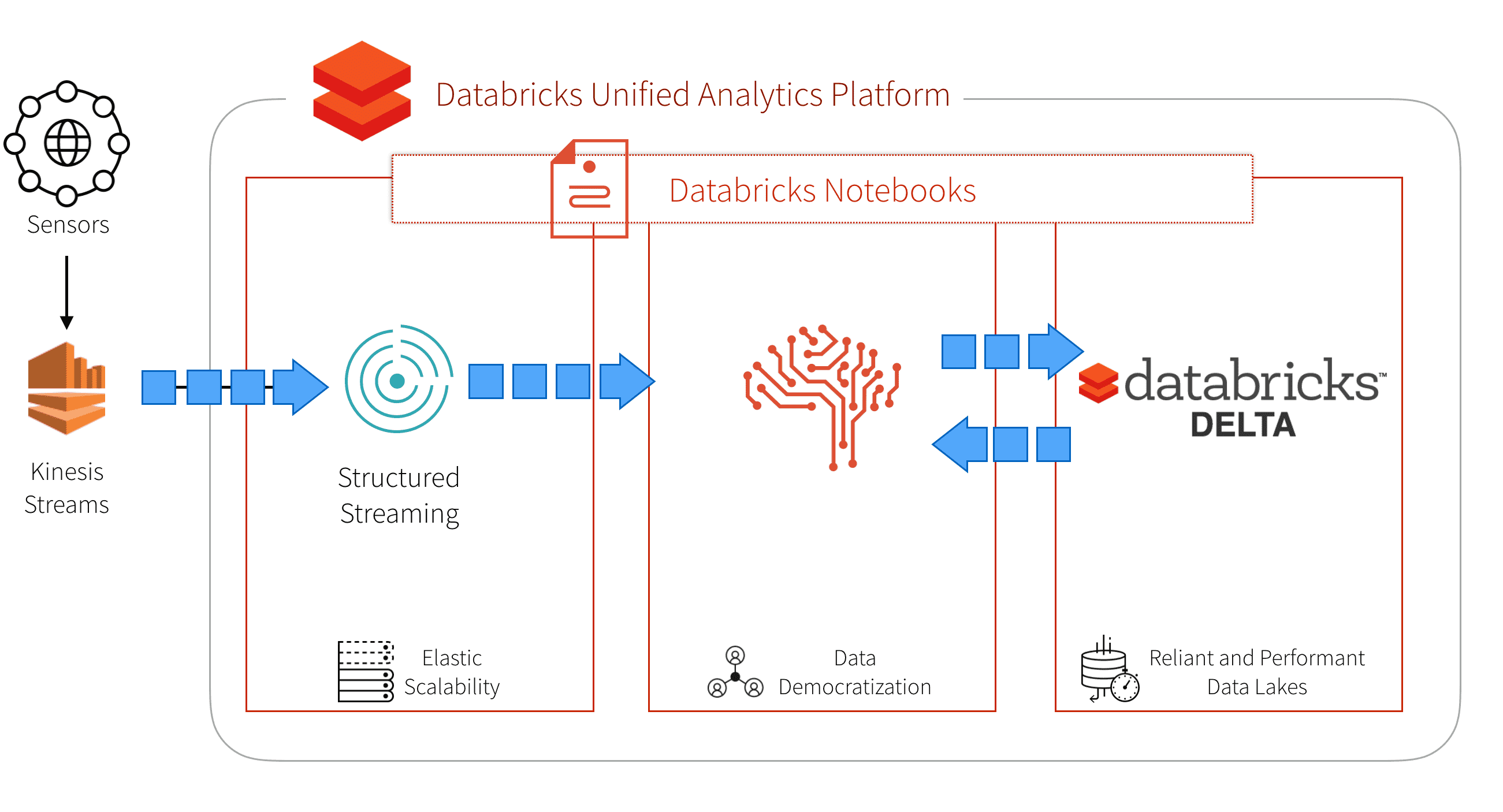
我们解决这些问题的方法是选择一个提供这些功能的统一平台。bob体育客户端下载Databricks提供了一个bob体育亚洲版统一分析平台bob体育客户端下载它将大数据和人工智能结合在一起,并允许组织中的不同角色聚集在一起,在一个工作空间中协作。Databricks统一分析平台的其他重要优势包括:bob体育亚洲版bob体育客户端下载
- 调动必要的资源,让数据科学家、数据工程师和数据分析师快速理解他们的数据。
- 是否有一个多云策略,允许每个人使用相同的协作工作空间Azure或AWS.
- 建立一组不同的实例类型组合,以优化运行您的工作负载
- 调度命令(包括REST API命令),允许您自动创建和自动终止您的集群。
- 在生产解决方案时,快速轻松地启用访问控制以分配权限,并为安全REST API调用启用访问令牌。
在这篇文章中,我们将向您展示如何通过以下方法使您的油气资产更加智能:
- 在Databricks中使用Spark Streaming来处理大量的传感器遥测。
- 构建和部署机器学习模型,以便在资产故障发生之前预测它们。
- 使用Databricks Delta创建实时数据库来存储和流传感器部件和资产。
建立你的运动流
为了预测灾难性故障,我们需要结合来自Kinesis、Spark Streaming和流式K-Means模型的资产传感器连续数据流。让我们开始使用下面的代码片段配置我们的Kinesis流。欲深入了解,请参阅Databricks -亚马逊运动集成.
// === Kinesis流的配置===val awsAccessKeyId =“您的访问密钥id”val awsSecretKey =“你的秘密钥匙”val kinesisStreamName =“你的流名”val kinesisRegion =“你的地区”//例如,"us-west-2"进口com.amazonaws.services.kinesis.model.PutRecordRequest进口com.amazonaws.services.kinesis.AmazonKinesisClientBuilder进口com.amazonaws.auth。{DefaultAWSCredentialsProviderChain, BasicAWSCredentials}进口java.nio.ByteBuffer进口scala.util.Random
凭证建立后,您可以运行Spark Streaming查询,从Kinesis读取单词,并使用以下代码片段对它们进行计数。
//建立Kinesis Streamval kinesis = spark.readStream.format (“运动”).option (“streamName”kinesisStreamName).option (“地区”kinesisRegion).option (“initialPosition”,“TRIM_HORIZON”).option (“awsAccessKey”awsAccessKeyId).option (“awsSecretKey”awsSecretKey).load ()//在Kinesis Stream上执行DataFrame查询val result = kinesis.selectExpr("lcase(CAST(数据为字符串))作为单词").groupBy ($“单词”).count ()//将输出显示为条形图显示器(结果)
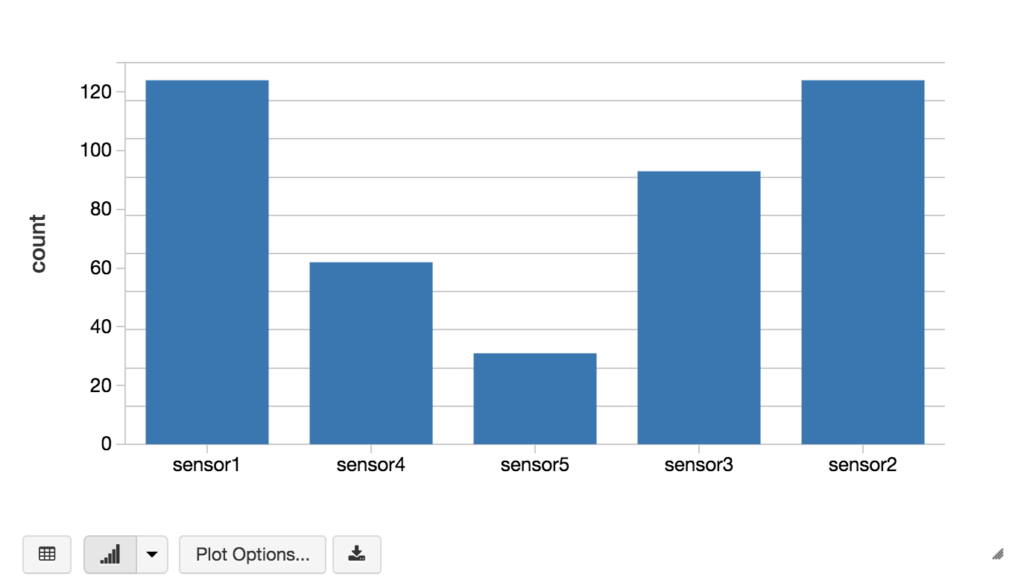
为了配置你自己的Kinesis流,你可以通过创建一个低层次的Kinesis客户端(比如下面的代码片段,每隔5秒循环一次)把这些话写到你的Kinesis流中。
//从AWS Java SDK创建底层Kinesis客户端val kinesisClient = AmazonKinesisClientBuilder.standard().withRegion (kinesisRegion).withCredentials (新AWSStaticCredentialsProvider (新BasicAWSCredentials (awsAccessKeyId awsSecretKey))).build ()println (s“把文字放到流媒体上kinesisStreamName美元")varlastSequenceNumber:字符串=零为(我
探索传感器数据
在我们建立模型来预测健康压缩机和损坏压缩机之前,让我们先做一些数据探索。首先,我们需要导入我们的健康和损坏的压缩机数据;下面的代码片段将CSV格式的健康压缩机数据导入Spark SQL DataFrame。
//读取正常压缩机读数(表示通过H1的前缀)val healthyCompressorsReadings=sqlContext.read.format(“com.databricks.spark.csv”). schema (StructType (StructField(“AN10”,倍增式,假)::StructField(“AN3”,倍增式,假)::StructField(“AN4”,倍增式,假)::StructField(“AN5”,倍增式,假)::StructField(“AN6”,倍增式,假)::StructField(“AN7”,倍增式,假)::StructField(“AN8”,倍增式,假)::StructField(“AN9”,倍增式,假)::StructField(“速度”,倍增式,假):: Nil)) .load(“/压缩机/ csv / H1 *”)//创建健康压缩机火花SQL表格healthyCompressorsReadings.write.mode (SaveMode.Overwrite) .saveAsTable(“compressor_healthy”)//读表格从拼花val compressor_healthy=表格(“compressor_healthy”)
我们还将数据保存为Spark SQL表,以便使用Spark SQL进行查询。例如,我们可以使用数据库显示命令查看损坏压缩机表的表统计信息。
显示器(compressor_damaged.describe ())

在使用以下代码片段随机抽取健康数据和损坏数据后:
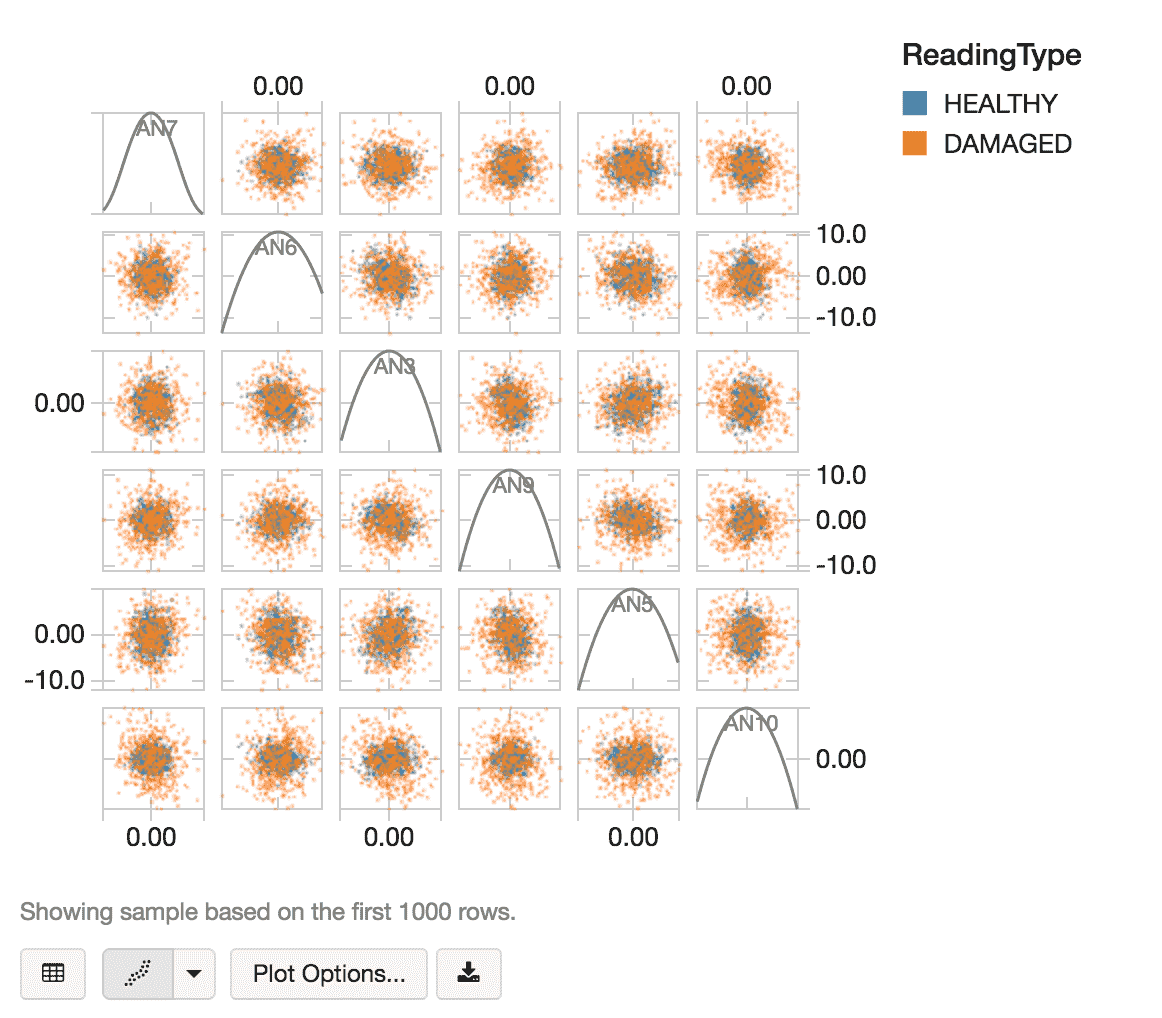
//获取健康和损坏压缩机的随机样本val randomSample = compressor_health . withcolumn (“ReadingType”点燃(“健康”)采样(假,500/4800000.0).union (compressor_damaged.withColumn (“ReadingType”点燃(“受损”)采样(假,500/4800000.0))
我们可以使用数据库显示命令使用散点图可视化我们的随机数据样本。
//查看压缩机健康与损坏读数散点图显示器(randomSample)
构建我们的模型
实现我们的预测维护模型的下一步是创建一个K-Means模型来聚类我们的数据集,以预测损坏和健康的压缩机。除了K-Means是一种流行且易于理解的聚类算法外,使用流K-Means模型还有一个好处,即允许我们轻松地在批处理和流场景中执行相同的模型。
我们要做的第一件事是确定最优k值(即最优簇数)。由于我们目前正在识别健康和受损之间的差异,直观地,k的值是2,但让我们验证一下。正如下面的代码片段所指出的,我们将构建一个ML管道,这样我们就可以很容易地为我们的新数据集(即流数据集上游)重用模型。我们的ML管道相对简单,使用VectorAssembler来定义涉及Air和Noise列(即前面有AN的列)的特征,并使用MinMaxScaler来缩放它。
进口org.apache.spark.ml._进口org.apache.spark.ml.feature._进口org.apache.spark.ml.clustering._进口org.apache.spark.mllib.linalg.Vectors//使用KMeansModelVal模型:数组[org.apache.spark.mllib.clustering。KMeansModel] =新数组(org.apache.spark.mllib.clustering.KMeansModel) (10)//使用VectorAssembler定义基于空气+噪声列的特征(并缩放它)val vectorAssembler =新VectorAssembler () .setInputCols (compressor_healthy.columns.filter (_.startsWith (“一个”))) .setOutputCol (“特征”)val mmScaler =新MinMaxScaler () .setInputCol (“特征”) .setOutputCol (“缩放”)//构建ML管道Val管道=新管道().setStages (数组(vectorAssembler mmScaler))//根据压缩机健康数据建立模型val prepModel = pipeline.fit(compressor_health)val prepData = prepModel.transform(compressor_health).cache()//迭代找到最好的K个值val maxIter =20.val maxK =5val findBestK =为(k
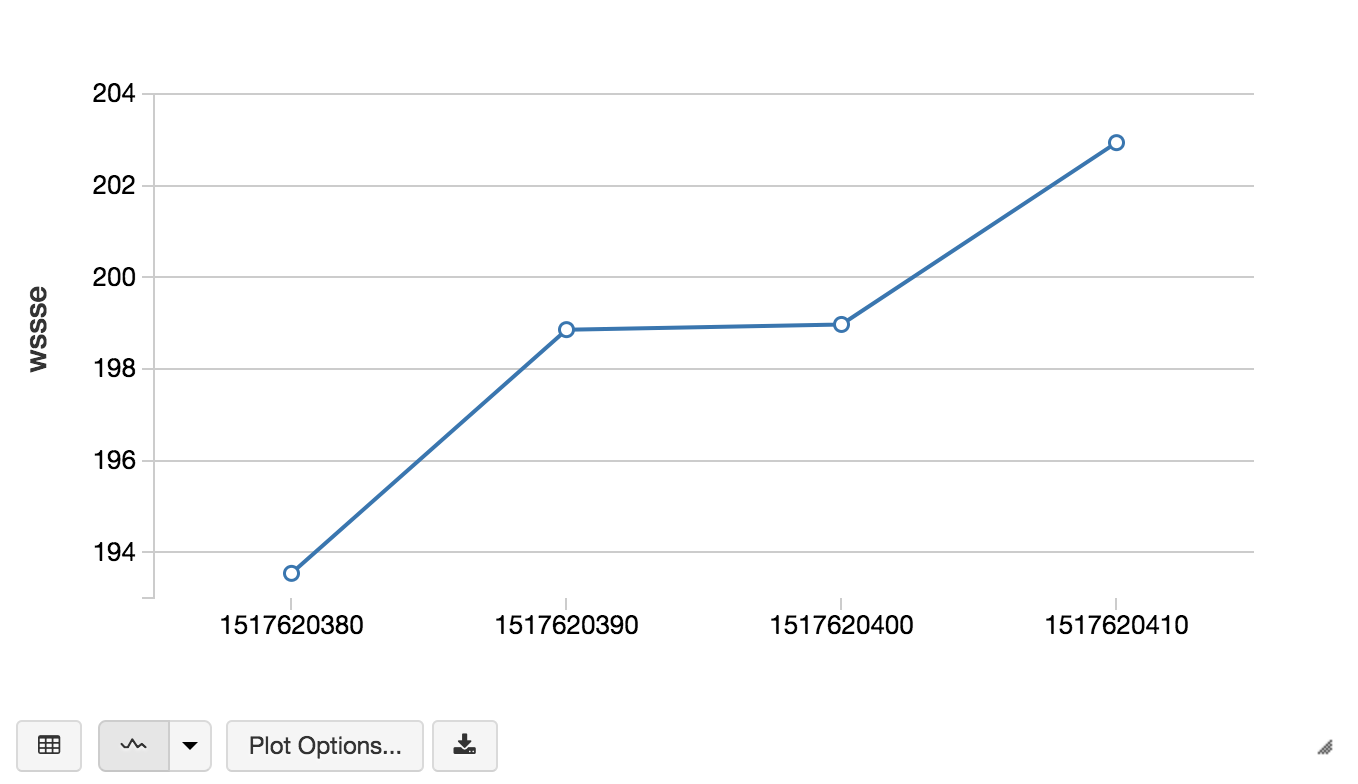
我们计算了一个数字的通过迭代来确定最佳k值,为目的的这演示,我们init</em>我们自己的k值[2…5]而且set the max iterations to 20. The goal is to iterate through the various k and WSSSEem >(在集总和的的平方错误)值;最优k值(理想数的簇)就是有一个“肘”在WSSSE图。我们还可以计算最高阶导数的这个图与下面的代码片段。
//计算导数的WSSSE val previousDf=kWssseDf。与Column("k", $"k"-1).withcolumnrename ("wssse", "previousWssse") val派生的wssse=previousDf。加入(kWssseDf“k”)。选择Expr("k", "previousWssse - wssse derivative").orderBy($"k")//找到重点与最高阶导数//即最优数量的集群是bestK=2val bestK=derivativeOfWssse。选择( (引领(“导数”,1).在(Window.orderBy(“k”))-美元“导数”)。作为(“nextDerivative”)(“k”).orderBy美元“nextDerivative”。desc) .rdd.map (_ (1) .first.asInstanceOf [Int]
现在我们已经确定了最优k值,现在可以用两个聚类构建模型。下面的代码片段创建了我们的KMeans模型(bestModel)与压缩机健康数据(prepData),并计算WSSSE (wssse).
//创建我们的kmeans模型Val kmeans =新KMeans ().setK (bestK).setSeed (1L).setMaxIter (One hundred.).setFeaturesCol (“缩放”)val bestModel = kmeans.fit(prepData)val wssse = bestModel.computeCost(prepData)/ /输出kmeans: org.apache.spark.ml.clustering.KMeans = kmeans_aeafe51274c3bestModel: org.apache.spark.ml. clusteringkmeansmodel = kmeans_aeafe51274c3wssse:双=329263.3539615829
通过将损坏的压缩机数据应用于相同的ML管道和模型,我们可以通过WSSSE值快速观察到健康压缩机与损坏压缩机之间的差异。
//计算损坏压缩机的WSSSEval prepdamagemodel = pipeline.fit(compressor_destroyed)val prepdamagedata = prepModel.transform(compressor_destroyed).cache()val bestDamagedModel = kmeans.fit(prepDamagedData)val wssse = bestDamagedModel.computeCost(prepDamagedData)/ /输出prepDamagedModel: org.apache.spark.ml.PipelineModel = pipeline_70af6bee9dadprepDamagedData: org.apache.spark.sql.Dataset [org.apache.spark.sql。行]= [AN10:双AN3:双...9多个字段)bestdamagemodel: org.apache.spark.ml.clustering.KMeansModel = kmeans_aeafe51274c3wssse:双=1440111.9276810554
使用流式K-Means部署模型
虽然我们有一个潜在可行的模型来预测压缩机故障,但实时(与批处理相比)执行这个模型允许我们构建一个连续应用程序不断接收资产传感器流。我们现在可以更早地预测压缩机故障,从而为我们提供更多的时间来修复或更换压缩机,以防灾难性故障。
下面的代码片段使用相同的方法创建流KMeans模型bestK的值。setK属性(即2个集群)。要深入了解流式K-Means算法,请参阅MLlib编程指南> MLlib聚类>流式K-Means.
//创建StreamingKMeans()模型val kMeansModel =新StreamingKMeans ().setDecayFactor (0.5).setK (2).setRandomCenters (8,0.1)
方法创建流函数StreamingContext计算每个小批的WSSSE。
//函数来创建一个新的StreamingContext并设置它def creatingFunc(): StreamingContext = {//创建一个StreamingContextVal SSC =新StreamingContext (sc,秒(batchIntervalSeconds))val batchInterval = Seconds(batchIntervalSeconds)ssc.remember(秒(300))
val dstream = ssc.queueStream(队列)//当DStream接收数据时,我们计算每个小批的WSSSE//并将此数据保存到DBFSkMeansModel.trainOn (dstream)dstream。为eachRDD {抽样= >val wssse = kMeansModel.latestModel().computeCost(rdd)val时间戳=系统。currentTimeMillis /1000sc.parallelize (Seq (WsseTimestamps(时间戳,wssse))) .toDF () .write.mode (SaveMode.Append) . json (“/ tmp /压缩机”)}println (创建函数,用于为压缩机故障预测创建新的StreamingContext)newContextCreated =真正的ssc}
随着流式K-Means模型和Spark Streaming函数的创建,下面的代码片段现在启动了我们的Spark Streaming上下文。
//执行Spark Streaming Contextval ssc = StreamingContext.getActiveOrCreate(creatingFunc)如果(newContextCreated) {println ("从当前定义的创建函数创建了新上下文")}其他的{println ("现有上下文正在运行或从检查点恢复,可能没有运行当前定义的创建函数")}//启动Spark Streaming上下文ssc.start ()
如Spark Streaming函数中所述,为了持久化数据,我们将时间戳和WSSSE值以JSON形式保存到DBFS(在本例中,在DBFS中)/ tmp /压缩机).文件DBFS持久化到blob存储,这样即使在终止集群之后也不会丢失数据。下面的代码片段允许您通过时间戳查看WSSSE计算流,从而允许您在接收传感器数据时预测压缩机的故障率。
//从DBFS读取StreamingKMeans()结果val compressorsResults = sqlContext.read.json(“/ tmp /压缩机”)//查看运行中的模型显示器(compressorsResults.orderBy (“t”))
我们可以依赖Apache Spark Streaming来处理我们所有的资产遥测,因为它提供了关于系统状态的强有力保证:在任何时候,应用程序的输出都相当于在数据的前缀上执行一个批处理作业。这种一致性规则使我们很容易推断过去的流媒体挑战。Spark Streaming in Databricks提供了轻松创建连续应用程序的功能,简化了流应用程序的维护,以及Databricks集成工作空间的功能。
使用Databricks Delta实时数据库重新训练你的模型
虽然我们有一个可行的流式K-Means模型,但当接收到数据的新行和/或新属性时,重新训练我们的模型是非常常见的。一个强大的选择是创建一个实时数据库,它能够存储您的遗留数据(例如健康和损坏的压缩机数据)和新事务,因为它们以一致的方式流式传输。为此,我们可以使用Databricks Delta,它提供了数据仓库的性能和可靠性(用于大量遗留压缩机数据),并允许“实时”更新(用于资产遥测)。
在前一节中,我们使用saveAsTable我们可以用使用δ选项,例如下面的代码片段。
//创建健康压缩机数据表格创建表格compressor_healthy (AN10双,AN3双,AN4双,AN5双,AN6双,AN7双,AN8双,AN9双,速度双)使用δOPTIONS (PATH "/compressors/delta/healthy/")
这个Spark SQL语句创建了一个Databricks Delta表,你可以在这个表上训练和再训练你的模型,它还提供:
- 通过事务保证确保数据完整性。
- 启用流写入的最一致视图。
- 通过索引和缓存加快查询速度。
总结
在这篇博客文章中,我们演示了如何使用Databricks统bob体育亚洲版一分析平台bob体育客户端下载通过将Spark Streaming、机器学习和Databricks Delta结合起来。在单个笔记本电脑中,您可以读取和写入Kinesis流,在ML管道中构建K-Means模型,并将模型应用于Spark Streaming,以便在接收数据时预测压缩机故障。使用Databricks统一分析平台,您bob体育亚洲版可以消除通常与此类数bob体育客户端下载据管道相关的数据工程复杂性,并轻松使用三种不同的数据范式——流、SQL和机器学习——以潜在地防止任何资产的故障。
阅读更多
有关Databricks Delta和结构化流的更多信息,请阅读以下来源: