
危机和幽灵在云中对大数据的工作负载的性能影响




2018年1月13日 在工程的博客

上周,两个行业安全漏洞的细节,被称为危机和幽灵,被释放。这些事迹使cross-VM和跨平台攻击通过允许不可信程序扫描其他程序的内存。
在砖上,用户可以执行任意代码的唯一地方是在虚拟机运行Apache火花集群。在VM, cross-customer隔离处理水平。砖上运行的云提供商,Azure和AWS,都宣布他们修补管理程序,防止cross-VM攻击。砖取决于我们的云提供商提供安全隔离的虚拟机监控程序在虚拟机和应用程序更新应足以防止演示跨租户攻击。
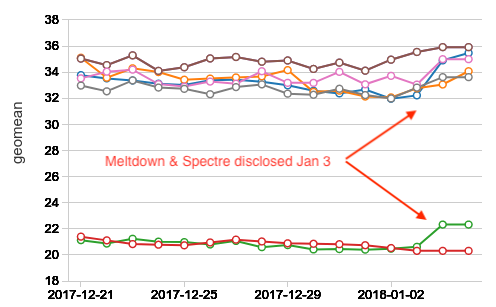
除了安全影响,可能我们的用户最关心程度的缓解策略引入的性能下降。在夜间绩效基准,我们注意到一些变化1月3日,当利用披露。我们初步评估,我们发现一个小退化AWS 3%在大多数情况下,5%的在某一特定情况下,虚拟机监控程序的更新。我们没有包括初步评估在Azure因为我们没有历史数据,我们需要有信心关于这样一个评估。
在这篇文章中,我们分析了潜在的性能造成的影响为危机和幽灵程序移植,使用我们的夜间性能基准。在一个后续的博客外,我们还提供利用的概述和缓解策略。
介绍
大数据应用程序最resource-demanding云计算工作负载。对于我们的一些客户,一个小减速系统可能导致数百万美元增加预算。这些功绩,关心安全后迫切的问题是:多少后将大数据负载减速hypervisor缓解由云提供商应用补丁?
正如前面所提到的,我们注意到一个小高峰后,1月3日在我们的内部性能指示板。偶尔会造成峰值随机变异的来源,所以我们必须等到我们有更多的数据以坚实的得出结论。现在,我们有了更多的数据点,它已经变得更加明显,管理程序更新对大数据的工作负载性能影响。
危机的缓解策略和幽灵影响代码路径执行虚拟函数调用和上下文切换(如线程切换、系统调用、磁盘I / O, I / O和网络中断)。
我们所知,没有报告存在工作量大数据系统在云中运行,通常运动从桌面或服务器应用程序非常不同的代码路径。虽然有很多的报告从“对性能的影响可以忽略不计”63%放缓FS-Mark我们已经看到最近的例子是7%到23%的Postgres的退化,我们的一些客户担心他们会观察Apache引发类似的性能影响。
然而,尽管都是数据系统,引发的数据平面(执行者)看起来一点也不像Postgres。项目的主要目标之一钨在火花2.0是消除尽可能多的虚拟函数分派代码生成。这个,有幸运的副作用减少危机的影响和幽灵应对当前的火花的执行。
火花的控制平面(司机)触发操作可以影响更多的移植。例如,网络rpc触发上下文切换和控制平面的代码往往执行更多的虚拟功能分派(由于使用面向对象编程和功能成为megamorphic)。好消息是,司机只负责调度和协调,并总体上较低的CPU利用率。因此,我们预计不如事务性数据库系统性能退化引发像Postgres。
方法
之前的基准测试结果,我们首先分享我们如何进行这种分析,利用夜间性能基准。
工作负载:我们的夜间基准包括数以百计的查询,包括所有99 TPC-DS查询,运行在两种最流行的大数据在AWS实例类型的工作负载(r3和i3)。这些查询用例覆盖不同的火花,从交互式查询扫描少量的数据深度分析扫描大量的查询。总体来说,它们代表了大数据云中的工作负载。
回到过去:部分原因公共基准测量这些程序补丁非常稀疏的影响是云供应商应用程序更改利用被披露后不久,和现在没有办法回到过去并执行控制实验应用补丁的机器。我们大多数科学计量需要运行相同的工作负载对一个针对修补应用补丁的数据中心和数据中心。缺席,我们利用夜间性能基准分析退化。
噪音:另外一个挑战就是,云计算本质上是嘈杂的,是任何共享资源和分布式系统。网络或存储性能可能随时间因不同的资源利用率。下面的图表显示了去年基准配置的运行时,任何程序之前修复。如图表所示,即使没有任何已知的重大更新,我们可以看到巨大的变化从运行运行性能。
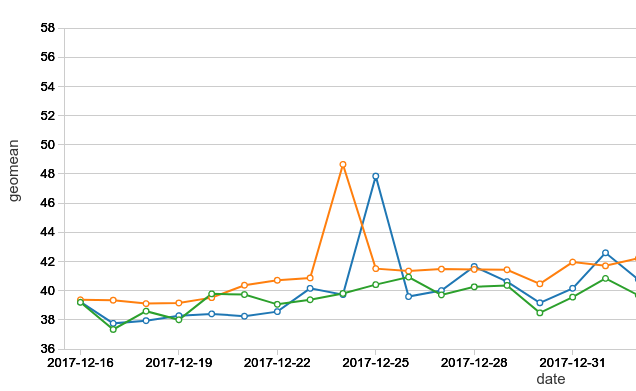
因此,我们需要一个足够数量的去除噪声的影响。因此我们不能使用一个运行,甚至2分,最后的性能配置。
幸运的是,我们确实有夜间运行绩效基准,我们积累了7天1月3日之前和之后的数据(日期似乎AWS补丁适用于我们的系统)。每天,数以百计的查询是运行在多个集群配置和版本,所以总体来说我们有成千上万的查询。
隔离效果的软件更改:虽然这些基准主要用来跟踪性能回归软件开发的目的,我们也运行旧版本的火花,建立性能基线。使用这些旧版本,我们可以隔离软件改进的效果。
我们也有额外的版本冒烟测试,运动更全面的配置和实例类型的矩阵,但他们并不经常运行。我们没有这些测试报告数据,因为我们觉得没有足够的数据点建立强有力的结论。
退化在Amazon Web服务
在AWS,我们观察到一个小自1月4日性能下降到5%。i3-series实例类型,我们在本地缓存数据NVMe ssd (砖缓存),我们观察到一个退化高达5%。r3-series实例类型,基准工作只读取数据从远程存储(S3),我们观察到一个更小的增加3%。i3实例类型的比例更大的衰退是由系统调用执行的大量阅读当地SSD的缓存。
下面的图表显示之前和之后的1月3日在AWS r3-series(内存优化)和i3-series集群(基于存储优化)。这两个测试都使用固定和集群大小相同的运行时版本。基准数据的平均值代表完整的运行时每天,总共7天前1月3日之前(蓝色)和1月3日7天后(红色)。我们排除1月3日,以防止部分结果。如前所述,i3-series有砖缓存启用本地ssd,导致大约一半的总执行时间(速度)r3-series相比的结果。
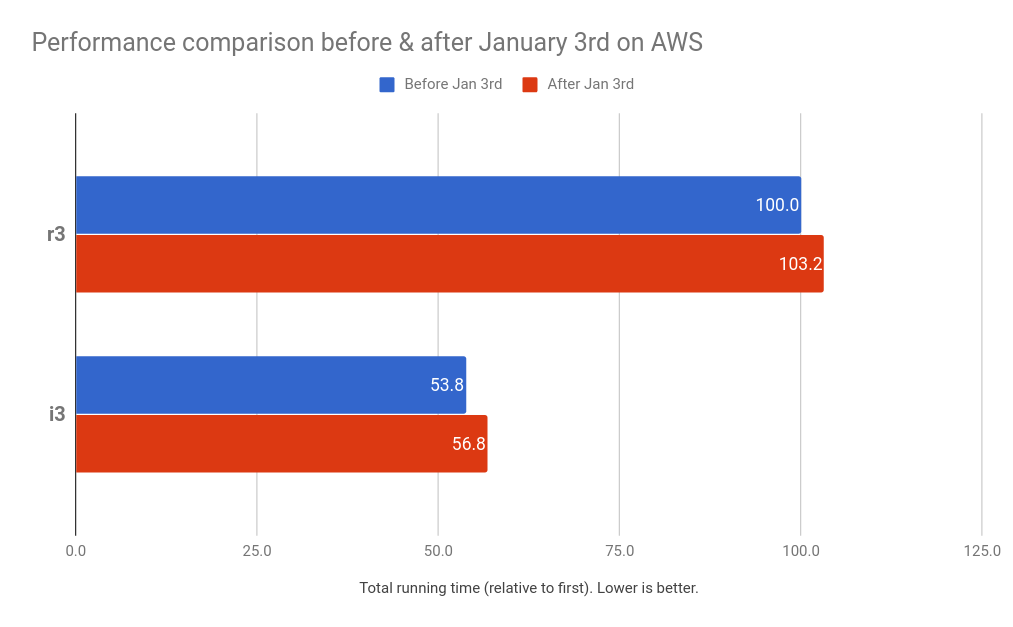
鉴于上述数据,有人可能会怀疑v i系列的不同退化。年代——r是由于不同的实例配置(和架构生成),或者由于砖缓存。我们不能回到过去,重复测试没有补丁在云中,隔离的影响砖缓存,我们首次运行的性能相比第一个查询r3和i3,发现,两个同样执行。也就是说,额外的退化是由于缓存。NVMe SSD缓存,CPU利用率更高,火花每秒处理更多的数据,并触发更多的I / O,比没有缓存。然而,更新和存储优化i3-series缓存完全相同的基准在大约一半的时间。
接下来是什么?
虽然很难是结论性的由于缺乏控制实验中,我们观察到一个小的性能下降(2 - 5%)在AWS管理程序更新。我们期望这种影响降低补丁实现改善随着时间的推移。
然而,我们还没有完成。整个事件仍在发生。管理程序更新应用的云供应商只减轻cross-VM攻击。整个行业正致力于缓解策略在内核和处理层次,以防止用户应用程序扫描内存他们不应该被允许。
我们的云计算厂商的快速反应这个问题重申砖的核心原则,移动云计算数据处理使安全问题迅速发现,减轻和固定。
即使我们的安全体系结构不依赖于内核或流程级别隔离,谨慎的态度我们也采取及时措施修补漏洞在这些层面。我们执行控制性能影响的实验,但我们还没有感觉到我们已经收集足够的数据报告。我们将尽快更新。
