
粗粒度的数据安全的最佳实践在砖


2017年8月23日 在bob体育客户端下载平台的博客
在砖,我们与数百家公司合作,把流血的边缘在各自的行业。我们想分享模式来保护数据,以便您的组织可以利用最佳实践而不是重建轮当你板砖的bob体育亚洲版统一的分析平台bob体育客户端下载。这篇文章主要是针对那些在他们的组织管理数据。这意味着控制对某些数据的访问和维护哪些用户可以访问哪些数据。
介绍和背景
之前的细节操作上你会做什么,让我们确保我们有正确的词汇,以确保你可以转身制定这个迅速在你的组织中。
DBFS
的砖文件系统(DBFS)是提供给每一位客户,由S3支持的文件系统。可伸缩的远远超过HDFS,适用于所有集群节点和提供了一个简单的分布式文件系统接口S3 bucket。
dbutils
dbutils是一个简单的工具来执行一些砖砖内部相关操作笔记本在Python中或在Scala中。他们提供了大量的S3 bucket命令来帮助您浏览;然而,最相关的fs模块。
运行下面的代码将别名S3 bucket作为挂载点。dbutils.fs。山(“s3a: / / data-science-prototype-bucket”、“/ mnt /原型”)
这是可用在所有集群节点的路径/ / mnt /原型。或者说,dbfs: / / mnt /原型
这意味着我们可以写出DataFrame这条路(和任何目录下),就像我们写HDFS,但DBFS将写入到S3 bucket。
df.write.parquet (“/ mnt /原型/比尔/ recommendation-engine-v1 /”)
简而言之,DBFS让S3似乎更像一个文件系统,挂载点做出具体S3 bucket的部分文件系统访问。这只是一个别名或快捷方式,允许一个S3物理路径重路由到另一个逻辑路径。自然,用户必须能够访问目的地S3 bucket为了访问数据。
接下来的几节将介绍不同的方法我们可以安全地访问S3 bucket。
我的角色和钥匙
在AWS上有两种不同的方法,您可以编写数据上传到S3。你可以做到的我的角色或者一个访问密钥。功能,我的角色和钥匙可以交替使用。你可以使用这些数据砖集群或结合DBFS使用它们。
当你安装一个桶一个S3路径使用DBFS如果路径是与我有关的角色,然后所有节点和用户在您的集群作为我的一部分作用会读和写访问,安装路径。例如,
dbutils.fs。山(“s3a: / / data-science-prototype-bucket”、“/ mnt /原型”)
只能读一个机器和一个我的角色有权访问特定的桶。
相比之下,当你安装一个水桶和一个AWS键和一个s3路径,当我们看到以下代码片段,
dbutils.fs.mount (“s3a: / /关键:(电子邮件保护)/”、“/ mnt /原型”)
那么这个挂载点可以在组织层面基于访问控制策略的关键。这意味着任何集群能够读取(和潜在的写)数据的挂载点。
粗粒度的控制数据访问
现在,我们介绍了各种定义的术语,让我们探索我们可以如何保护我们的数据。所有这些表现在行政级别的访问控制措施。也就是说,个人用户不应该设置这些,管理员应该这么做。
请注意:因为钥匙可以被复制或妥协,他们不是最安全的方式来访问数据源。一般来说,你应该支持我角色的钥匙。
最安全:明确分离的访问
最安全的设置中可以进行砖是定义我的角色当你创建集群。我的角色,添加授予访问权限,如读和写,S3 bucket。使用集群访问控制,可以控制哪些用户可以访问哪些数据,通过这些我的角色。
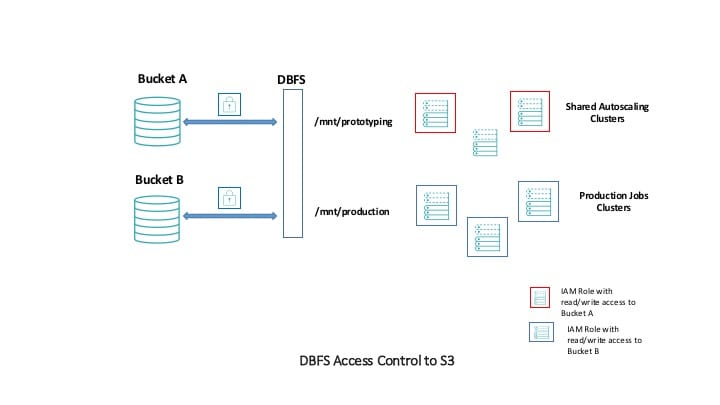
S3 bucket是左边,我们有两种类型的集群,集群共享自动定量对开发工作有读写权限原型设计S3 bucket(和挂载点)和生产集群能读和写的生产桶(B)。
它应该自不待言,但下面的代码,运行在自动定量或共享砖Serverless集群,
df.write.parquet (“/ mnt /生产/一些/位置”)
会失败,因为我的角色相关的集群不包括访问权斗B。
这是一个常见的模式对于工程组织想要限制在集群级别的访问希望确保生产数据并不是与原型混合数据。政策对这些我的角色可能是一个例子。
{“版本”:“2012-10-17”,“声明”:【{“效应”:“允许”,“行动”:【“s3: ListBucket”),“资源”:【“攻击:aws: s3:::桶/ *”]},{“效应”:“允许”,“行动”:【“s3: propertynames”,“s3: GetObject”,“s3: DeleteObject”),“资源”:【“攻击:aws: s3:::桶/ *”]}]}安全:一个协作访问
另一个相似但略有更不安全的模式更适合数据科学团队,跨集群合作工作。在这种情况下,一些数据只读从所有集群,例如,对于训练和测试不同的数据科学模型但写信给那个位置应该是一个享有特权的行动。在此体系结构中,我们将挂载两个桶的钥匙。生产桶安装只读权限。当使用DBFS,这些键会隐藏(不像使用原始S3)。或者,您也可以指定只读访问我的角色。然而,这不会山,默认情况下,可以在所有集群。你要一定要开始一个集群和一个我的角色。
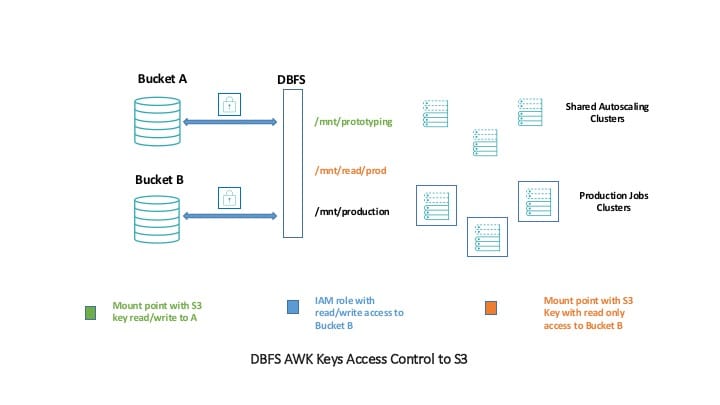
这意味着任何集群上下面的代码就可以了。
spark.read.parquet (“/ mnt /读/刺激/一些/数据”)
然而,这段代码会失败在任何集群。
df.write.parquet (“/ mnt /读/刺激/一些/数据”)
这是因为S3键没有适当的权限。在此结构中,你会注意到,我们可以以多种方式相同的S3 bucket山;我们甚至可以挂载不同的前缀(目录)到不同的位置。
写数据的唯一方法生产桶是使用适当的我的角色和写的具体位置,因为我们在以下代码片段。
df.write.parquet (“/ mnt /生产/一些/数据/位置”)
这种模式可以帮助管理员确保生产数据不是由用户同时还意外地覆盖使终端用户能够使用它更一般。
至少安全:只有钥匙
最后访问模式访问S3 bucket是只使用AWS访问键。因为钥匙可以很容易地复制或破坏,我们不推荐这种砖的数据访问模式。
结论
在这篇文章中,我们概述了安全的一些最佳实践和控制访问您的数据对砖的bob体育亚洲版统一的分析平台bob体育客户端下载。DBFS,我们可以挂载相同的桶多个目录使用AWS密钥以及我的角色。我们可以使用这些机制优势,做一些数据通常用于阅读但不能写作。
下一篇文章将介绍如何解决细粒度的访问控制砖企业安全(db)。