
让深度学习变得简单的愿景




当MapReduce在15年前被引入时,它让世界看到了未来。硅谷科技公司的工程师们第一次可以分析整个互联网。然而,MapReduce提供了难以使用的低级api,因此,这个“超级大国”是一种奢侈——只有一小部分拥有大量资源的高度复杂的工程师才能负担得起它。
今天,深度学习已经达到了它的“MapReduce”点:它已经展示了它的潜力;它是人工智能的“超级大国”。它的成就在几年前是不可想象的:自动驾驶汽车和AlphaGo会被视为奇迹。
然而,今天利用深度学习的超级能力就像昨天的大数据一样具有挑战性:由于底层api,深度学习框架具有陡峭的学习曲线;向外扩展分布式硬件需要大量的手工工作;即使有时间和资源的组合,要取得成功也需要繁琐的摆弄和试验参数。深度学习通常被称为“黑魔法”。
七年前,我们一组人启动了Spark项目,其唯一目标是通过提供高级api和统一引擎来进行机器学习、ETL、流和交互式SQL,使大数据的“超级能力”“民主化”。今天,Apache Spark使得从软件工程师到SQL分析师的每个人都可以访问大数据。
继续我们的民主化愿景,我们激动地宣布深度学习管道,一个新的开源库,旨在使每个人都能轻松地将可扩展的深度学习集成到他们的工作流程中,从机器学习从业者到业务分析师。
深度学习管道构建在Apache Spark的基础上毫升管道用于培训,并使用Spark DataFrames和SQL部署模型。它包含了用于深度学习常见方面的高级api,因此它们可以在几行代码中高效地完成:
- 图片加载
- 在Spark ML管道中应用预训练模型作为变压器
- 转移学习
- 分布式超参数调优
- 在数据框架和SQL中部署模型
在接下来的文章中,我们将通过例子详细描述这些特性。要在Databricks上尝试这些和更多的例子,请查看笔记本深度学习管道在Databricks.
图片加载
在图像上应用深度学习的第一步是加载图像的能力。深度学习管道包括实用函数,可以将数百万张图像加载到DataFrame中,并以分布式方式自动解码它们,允许大规模操作。
df = image . readimages (“/数据/模板”)我们还在努力增加对更多数据类型的支持,比如文本和时间序列。
应用预训练模型进行可扩展预测
深度学习管道支持用Spark以分布式的方式运行预训练的模型,可用于批处理和流数据处理.它包含了一些最流行的模型,使用户能够开始使用深度学习,而不需要花费昂贵的训练模型的步骤。例如,下面的代码使用最先进的用于图像分类的卷积神经网络(CNN)模型InceptionV3创建了一个Spark预测管道,并预测我们刚刚加载的图像中的对象。当然,这个预测是与Spark带来的所有好处并行进行的:
从sparkdl进口readImages, DeepImagePredictor预测器= DeepImagePredictor(inputCol=“图像”outputCol =“predicted_labels”modelName =“InceptionV3”)Predictions_df = predictor.transform(df)除了使用内置型号外,用户还可以插入Keras模型而且TensorFlowSpark预测管道中的图表。这将单节点工具上的任何单节点模型转变为可以在大量数据上以分布式方式应用的模型。
砖的bob体育亚洲版统一分析平台bob体育客户端下载,如果选择基于gpu的集群,计算密集型部分将自动在gpu上运行,以获得最佳效率。
转移学习
当预训练模型适合手头的任务时,它们非常有用,但它们通常没有针对用户正在处理的特定数据集进行优化。例如,InceptionV3是一个针对1000个类别的图像分类进行优化的模型,但我们的领域可能是犬种分类。深度学习中常用的技术是迁移学习,它使为类似任务训练的模型适应手头的任务。与从头开始训练一个新模型相比,迁移学习需要的数据和资源要少得多。这就是为什么迁移学习已经成为许多现实世界用例中的首选方法,例如癌症检测.
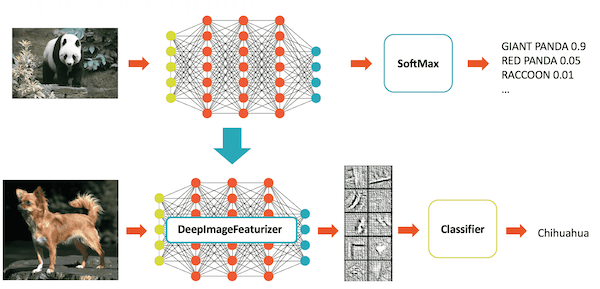
深度学习管道实现了快速迁移学习的概念Featurizer.下面的例子结合了InceptionV3模型和Spark中的逻辑回归,以使InceptionV3适应我们特定的领域。DeepImageFeaturizer自动剥离预训练神经网络的最后一层,并使用所有前一层的输出作为逻辑回归算法的特征。由于逻辑回归是一种简单而快速的算法,这种迁移学习训练可以使用比从头开始训练深度学习模型所需的图像少得多的图像快速收敛。
从sparkdl进口DeepImageFeaturizer从pyspark.ml.classification进口LogisticRegression(modelName= .“InceptionV3”)lr = LogisticRegression()p = Pipeline(stage =[featurizer, lr])# train_images_df =…#加载图像和标签的数据集模型= p.fit(train_images_df)分布式超参数调优
要在深度学习中获得最佳结果,需要对训练参数的不同值进行试验,这是一个被称为超参数调优的重要步骤。由于深度学习管道支持将深度学习训练作为Spark机器学习管道中的一个步骤,用户可以依赖Spark中已经内置的超参数调优基础设施。
下面的代码插入Keras Estimator,并使用交叉验证的网格搜索执行超参数调优:
myEstimator = KerasImageFileEstimator(inputCol=“输入”,outputCol =“输出”,modelFile =“/ my_models / model.h5”,imageLoader = _loadProcessKeras)kerasparams = {“batch_size”:10时代:10}kerasParams2 = {“batch_size”:5时代:20.}
myParamMaps =ParamGridBuilder () \.addGrid (myEstimator。kerasParams, [kerasParams, kerasParams]) \.build ()
cv =交叉验证器(myEstimator, myEvaluator, myParamMaps)cvModel = cv.fit()kerasTransformer = cvModel.bestModel# KerasTransformer类型在SQL中部署模型
一旦数据科学家构建了所需的模型,深度学习管道就可以简单地将其作为SQL中的函数公开,因此组织中的任何人都可以使用它——数据工程师、数据科学家、业务分析师,任何人。
sparkdl.registerKerasUDF (“img_classify”,“/ mymodels / dogmodel.h5”)接下来,组织中的任何用户都可以在SQL中应用预测:
选择Image, img_classification (Image)标签从图片在哪里包含(“吉娃娃”标签)类似的功能在DataFrame编程API中也适用于所有支持的语言(Python, Scala, Java, R)。与可伸缩预测类似,此功能既适用于批处理,也适用于扩展预测结构化流.
结论
在这篇博文中,我们介绍了深度学习管道,一个新的库,使深度学习更容易使用和扩展。虽然这只是一个开始,但我们相信深度学习管道有潜力完成Spark对大数据所做的事情:让每个人都能接触到深度学习“超级大国”。
本系列的后续文章将更详细地介绍库中的各种工具:大规模图像操作、迁移学习、大规模预测,以及在SQL中实现深度学习。
要了解BOB低频彩更多关于图书馆的信息,请查看砖的笔记本以及github库.我们鼓励您给我们反馈。或者更好的是,成为一名贡献者,帮助将可扩展的深度学习的力量带给每个人。