
检测大规模滥用:优步工程中的局部敏感哈希


这是一个跨博客文章Databricks和Uber Engineering之间的合作。倪云是Uber机器学习平台团队的软件工程师,Kelvin Chu是Uber复杂数据处理/语音团队的技术首席工程师,bob体育客户端下载Joseph Bradley是Databricks机器学习团队的软件工程师。
全球每天有500万次优步出行,对于优步工程师来说,确保数据的准确性非常重要。如果使用正确,元数据和聚合数据可以快速检测到平台滥用,从垃圾邮件到虚假账户和支付欺诈。bob体育客户端下载放大正确的数据信号使检测更加精确,从而更加可靠。
为了在我们的系统和其他系统中解决这一挑战,优步工程和Databricks共同努力局部敏感哈希(LSH)来Apache Spark 2.1.LSH是一种随机算法和哈希技术,通常用于大规模机器学习任务,包括聚类和近似最近邻搜索.
在本文中,我们将演示Uber如何使用这个强大的工具大规模地检测欺诈旅行。
为什么激光冲徊化?
在Uber Engineering实现LSH之前,我们使用N^2方法来筛选行程;虽然准确,但对于Uber的规模和规模来说,N^2的方法最终过于耗时、体积密集型和硬件依赖。
LSH的一般思想是使用一组函数(称为LSH族)将数据点散列到桶中,这样彼此靠近的数据点大概率位于相同的桶中,而彼此远离的数据点可能位于不同的桶中。这样可以更容易地识别不同程度重叠的行程。
作为参考,LSH是一种多用途技术,有无数的应用,包括:
- Near-duplicate检测:LSH通常用于删除大量的文档、网页和其他文件。
- 全基因组关联研究:生物学家经常使用LSH在基因组数据库中识别相似的基因表达。
- 大规模图像搜索:谷歌使用LSH和PageRank来构建他们的图像搜索技术VisualRank.
- 音频/视频指纹识别:在多媒体技术中,LSH作为a /V数据的指纹识别技术被广泛应用。
Uber的LSH
优步的主要LSH用例是基于空间属性来检测类似的行程,这是一种识别欺诈司机的方法。Uber工程师介绍了这个用例2016 Spark峰会期间,他们讨论了我们团队在Spark框架上使用LSH广播加入所有旅行并筛选虚假旅行的动机。我们在Spark上使用LSH的动机有三个方面:
- Spark是Uber运营中不可或缺的一部分,目前许多内部团队使用Spark进行各种类型的复杂数据处理,包括机器学习、空间数据处理、时间序列计算、分析和预测,以及临时数据科学探索。事实上,Uber几乎使用了所有Spark组件,比如MLlib,火花SQL,火花流,直接抽样同时处理YARN和Mesos;因为我们的基础设施工具是围绕Spark构建的,我们的工程师可以轻松地创建和管理Spark应用程序。
- Spark可以在进行任何实际的机器学习之前有效地进行数据清理和特征工程,从而使数字处理速度更快。Uber收集的大量数据使得通过基本方法解决这个问题不可扩展,而且非常缓慢。
- 我们不需要这个方程的精确解,所以不需要购买和维护额外的硬件。在这种情况下,近似为我们提供了足够的信息来对潜在的欺诈活动做出判断,在这种情况下,它足以解决我们的问题。LSH允许我们用一些精度进行交易,以节省大量硬件资源。
出于这些原因,通过在Spark上部署LSH来解决问题是我们业务目标的正确选择:规模、规模、再规模。
在高层次上,我们使用LSH的方法有三个步骤。首先,我们为每个行程创建一个特征向量,将其分解为大小相等的区域段。然后,对向量进行哈希MinHash为Jaccard距离函数。最后,我们可以批量或批量地进行相似连接再实时搜索。与检测欺诈的基本暴力方法相比,我们的数据集使Spark作业的完成速度快了一个数量级(从使用N²方法的55小时到使用LSH方法的4小时)。
API教程
为了更好地演示LSH是如何工作的,我们将通过一个在维基百科提取(WEX)数据集寻找类似的文章。
每个LSH族都与它的度量空间相关联。在Spark 2.1中,有两个LSH Estimators:
- BucketedRandomProjectionLSH为欧氏距离
- MinHashLSH表示Jaccard Distance
在这个场景中,我们将使用MinHashLSH,因为我们将使用字数的实值特征向量。
加载原始数据
在设置我们的Spark集群和安装之后WEX数据集,我们上传WEX数据样本到HDFS基于我们的集群大小。在Spark shell中,我们加载HDFS中的示例数据
//读取RDD从HDFS进口org.apache.spark.ml.feature._进口org.apache.spark.ml.linalg._进口org.apache.spark.sql.types._Val df = spark.read.option(“分隔符”,“t \”) . csv (“/ user / hadoop / testdata.tsv”)val dfuse = df.select(col(“_c1”).作为(“标题”)、坳(“_c4”).作为(“内容”))。过滤器(坳(“内容”) == null)dfUsed.show ()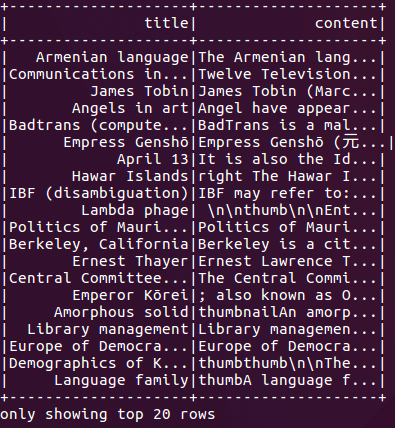
图1显示了前面代码的结果,按标题和主题显示文章。我们将使用内容作为我们的哈希键,并在接下来的实验中近似地找到类似的维基百科文章。
准备特征向量
MinHash是一种非常常见的LSH技术,用于快速估计两个集之间的相似程度。在Spark中实现的MinHashLSH中,我们将每个集合表示为二进制稀疏向量。在这一步中,我们将把维基百科文章的内容转换为向量。
使用下面的代码进行特征工程,我们将文章内容分成单词(Tokenizer),创建单词计数的特征向量(CountVectorizer),并删除空文章:
//标记维基内容Val tokenizer =新记号赋予器().setInputCol (“内容”) .setOutputCol (“单词”)val worddf = tokenizer.transform(dfuse)//每个wiki内容的字数向量val vocabSize =1000000val cvModel: CountVectorizerModel =新CountVectorizer () .setInputCol (“单词”) .setOutputCol (“特征”) .setVocabSize vocabSize .setMinDF (10) .fit (wordsDf)val isNoneZeroVector = udf({v:向量= >v.numNonzeros >0}, DataTypes.BooleanType)val vectorizedDf = cvModel.transform(worddf).filter(isNoneZeroVector(col(“特征”))) .select(坳(“标题”)、坳(“特征”))vectorizedDf.show ()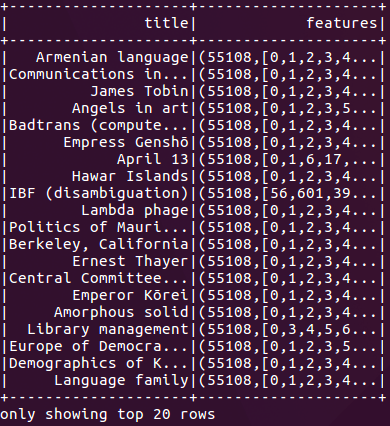
拟合和查询LSH模型
为了使用MinHashLSH,我们首先用下面的命令在我们的特征数据上拟合一个MinHashLSH模型:
Val mh =新MinHashLSH () .setNumHashTables (3.) .setInputCol (“特征”) .setOutputCol (“hashValues”)val模型= mh.fit(vectorizedDf)我们可以使用LSH模型进行几种类型的查询,但为了本教程的目的,我们首先在数据集上运行一个特征转换:
model.transform (vectorizedDf)。显示()这个命令为我们提供了哈希值,这对于手动连接和特性生成非常有用。
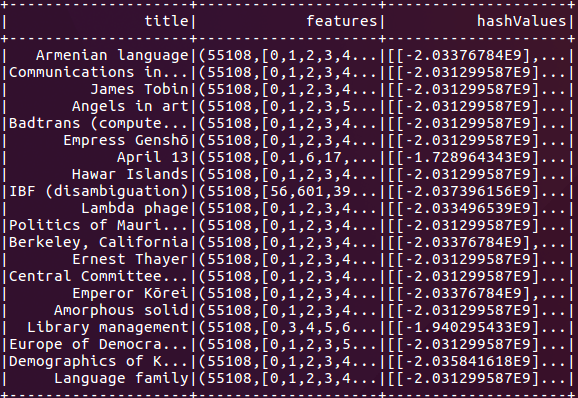
接下来,我们运行近似最近邻搜索,以找到最接近目标的数据点。为了便于演示,我们搜索内容与短语大致匹配的文章美国.
val关键=向量。稀疏(vocabSize Seq (cvModel.vocabulary.indexOf(“联合”),1.0), (cvModel.vocabulary.indexOf(“州”),1.0)))val k=40模型。approximate nearestneighbors (vectorizedDf, key, k)。显示()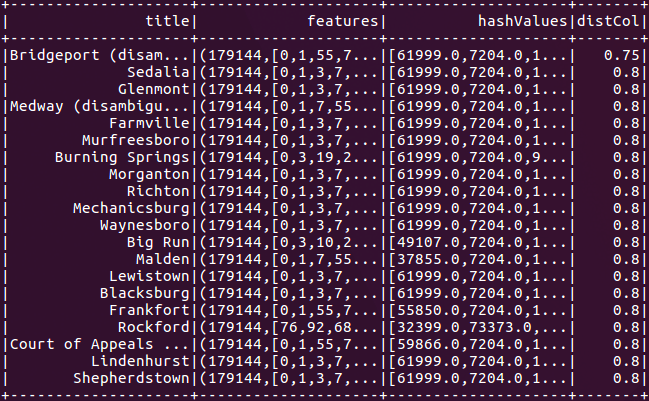
最后,我们运行近似相似度连接,在同一数据集中找到相似的文章对:
//自我加入val阈值=0.8模型。approxSimilarityJoin(vectorizedDf, vectorizedDf, threshold)。过滤器("distCol != 0")。显示()当我们使用自连接时,我们也可以连接不同的数据集以获得相同的结果。
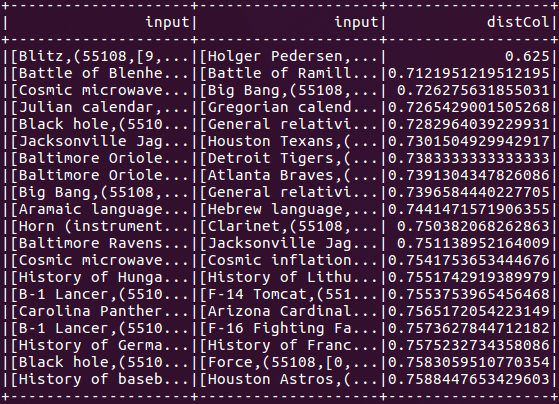
图5演示了如何设置的数目哈希表.对于近似相似连接和近似最近邻命令,可以使用哈希表的数量在运行时间和误报率(或者).增加哈希表的数量将提高准确性(这是积极的),但也会增加程序的通信成本和运行时间。缺省情况下,哈希表的数量设置为1。
为了获得在Spark 2.1中使用LSH的额外练习,您还可以在Spark发行版中运行较小的示例BucketRandomProjectionLSH而且MinHashLSH.
性能测试
为了评估性能,我们在WEX数据集上对MinHashLSH的实现进行了基准测试。使用AWS云,我们使用了16个执行程序(m3。xlarge实例)在WEX数据集样本上执行近似近邻搜索和近似相似连接。
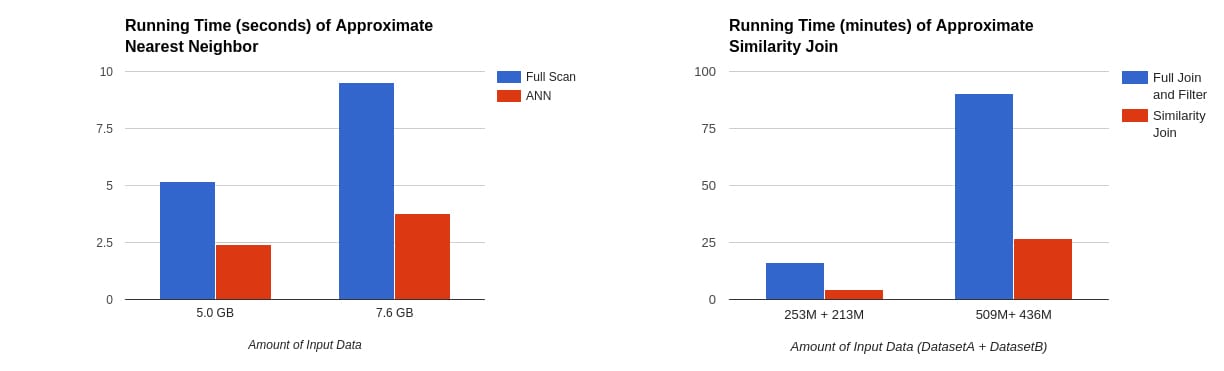
在上面的表中,我们可以看到,当哈希表的数量设置为5时,近似近邻的运行速度比完全扫描快2倍,而近似相似连接的运行速度快3 -5倍,这取决于输出行数和哈希表的数量。
我们的实验还表明,尽管它们的运行时间短,但与暴力方法的结果相比,该算法获得了较高的精度。同时,近似近邻搜索对返回的40行达到了85%的准确率,而近似相似性连接成功地找到了93%的附近行对。这种速度与准确性之间的权衡使得LSH成为一个强大的工具,可以每天从tb级的数据中检测欺诈旅行。
下一个步骤
虽然我们的LSH模型已经帮助优步识别欺诈司机行为,但我们的工作还远远没有完成。在LSH的初始实现期间,我们计划在未来的版本中部署大量的特性。高优先级特性包括:
- 火星- 18450:除了指定完成搜索所需的哈希表的数量外,这个新特性还可以定义每个哈希表中的哈希函数的数量。这一变化也将为AND/ or化合物扩增提供全面支持。
- 火星- 18082&火星- 18083:我们还想实现其他的LSH族。这两个更新将支持对两个数据点之间的汉明距离进行位采样,并支持对余弦距离进行随机投影符号,这通常用于机器学习任务。
- 火星- 18454:第三个特性将改进近似最近邻搜索的API。这种新的搜索,多探针相似度搜索可以提高搜索质量,而不需要大量的哈希表。
我们欢迎您的反馈,我们将继续开发和扩展我们的项目,以纳入上述功能和许多其他功能。