
介绍Apache火花2.0




今天,我们很高兴宣布的整体可用性Apache 2.0火花在砖上。该版本基于社区已经学到的东西在过去的两年里,加倍的用户喜欢什么和修复的痛苦点。这篇文章总结了三大themes-easier,更快,聪明包含2.0火花。我们也探索他们中的许多人在我们的更多细节选集火花2.0的内容。
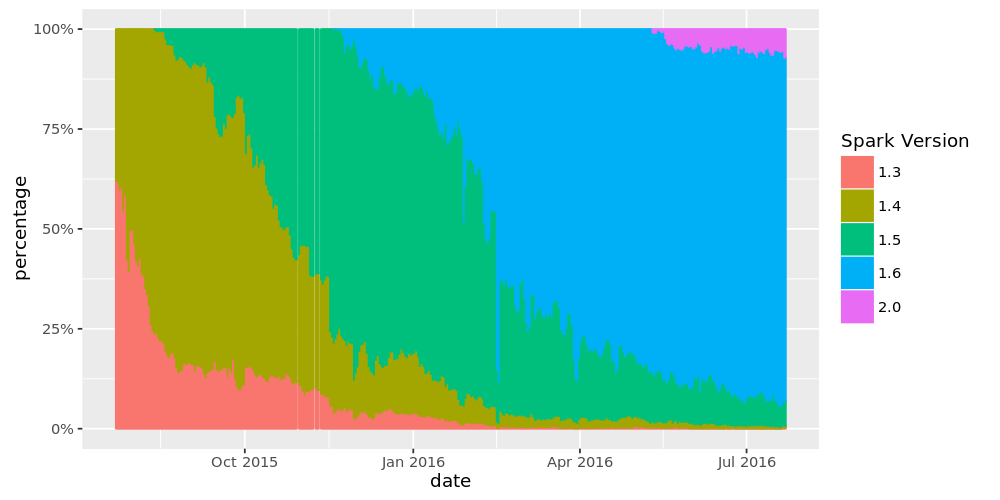
两个月前,我们推出了一个预览版的Apache 2.0火花砖。可以看到在下面的图表中,10%的集群已经使用这个版本,客户试验新功能并给我们反馈。感谢这次经历,我们兴奋的第一个商业供应商支持火花2.0。
现在,让我们深入的新在Apache 2.0火花。
简单:ANSI SQL和流线型的api
我们自豪的火花的一件事是简单的api,直观的表达。火花2.0继续这一传统,关注两个方面:(1)标准SQL支持和(2)统一DataFrame /数据API。
在SQL方面,我们明显扩大引发的SQL支持,通过引入一个新的ANSI SQL解析器和子查询。火花2.0可以运行所有的99 TPC-DS查询,需要许多SQL: 2003的特性。因为SQL的主要接口之一火花,这些扩展功能大大减少移植遗留应用程序的工作。
在编程API方面,我们有流线型的火花的API:
- Scala中的统一DataFrames和数据集/ Java:在火花2.0开始,DataFrame只是一个类型别名数据集的行。类型的方法(如。
地图,过滤器,groupByKey(如)和无类型的方法。选择,groupBy)数据集类上都是可用的。同样,这一新的数据接口是抽象相结合用于结构化流。由于编译时类型安全不是一个特性在Python和R,数据集的概念并不适用于这些语言api。相反,DataFrame仍是主界面,类似于这些语言的单节点数据帧的概念。得到一个偷看的这个博客这些api背后的故事。 - SparkSession:一个新的切入点,取代SQLContext HiveContext。DataFrame API,用户的一个共同的源引发的混乱的“上下文”。注意,老SQLContext和HiveContext类仍保持向后兼容性。
- 更简单、更高性能蓄电池API:我们已经设计了一个新的蓄电池API有一个简单的类型层次结构和支持基本类型的专门化。旧蓄电池API已经弃用,但保留向后兼容性
- DataFrame-based机器学习API中作为主要毫升API:2.0与火花,spark.ml包,以其“管道”API,将成为主要的机器学习API。原来的火花。mllib包保存下来,未来的发展重点是DataFrame-based API。
- 机器学习管道持久性:用户现在可以保存和加载机器学习管道和模型在所有编程语言支持的火花。看到这篇博客为更多的细节。
- 分布式算法R:增加了对广义线性模型的支持(GLM),朴素贝叶斯、生存回归,和k - means R。
- 用户定义的函数(udf) R:添加支持运行分区级别udf(斑纹和新闻出版总署)和hyper-parameter调优(拉普兰人)。
更快:Apache火花作为编译器
根据我们的2015年引发调查,91%的用户认为Apache火花的性能是最重要的方面。因此,性能优化一直专注在我们的火花的发展。在我们开始计划贡献2.0火花,我们问自己一个问题:火花已经很快,但我们能把它的边界,使火花快10倍?
这个问题让我们从根本上重新思考我们构建的方式引发的物理执行层。当你看到在现代数据引擎(例如火花或其他MPP数据库),大多数CPU周期花在无用的工作,如制作虚拟函数调用或读/写中间数据CPU缓存或内存。通过减少CPU周期的数量优化性能浪费在这些无用的工作已经很长一段时间的重点现代编译器。
火花2.0附带第二代钨引擎。这个引擎构建在思想与现代编译器和MPP数据库和它们适用于火花工作负载。主要的思想是排放优化代码在运行时崩溃整个查询到一个函数,消除虚拟函数调用和中间数据利用CPU寄存器。我们称之为技术”舞台的代码生成。”
给你一个急转弯,我们测量过程所花费的时间(纳秒)一行在一个核心的一些运营商火花1.6 vs 2.0火花。下表显示了改善火花2.0。火花1.6还包括一个表达式中使用代码生成技术,一些先进的商业数据库,但正如你所看到的,许多运营商成为与舞台代码生成快一个数量级。
| 原始的 | 火花1.6 | 火花2.0 |
|---|---|---|
| 过滤器 | 15 ns | 1.1 ns |
| 和w / o组 | 14 ns | 0.9 ns |
| 和w /组 | 79纳秒 | 10.7 ns |
| 散列连接 | 115纳秒 | 4.0 ns |
| 排序熵(8位) | 620纳秒 | 5.3 ns |
| 排序熵(64位) | 620纳秒 | 40 ns |
| 分类合并加入 | 750纳秒 | 700纳秒 |
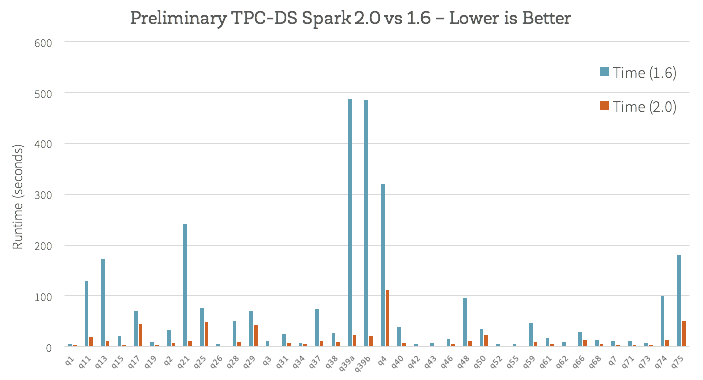
端到端查询这个新引擎是如何工作的?我们做了一些初步分析使用TPC-DS查询比较1.6火花,火花2.0:
舞台之外的代码生成来提高性能,很多工作也进入改善催化剂优化器等通用查询优化nullability传播,以及一个新的矢量化铺解码器,拼花扫描吞吐量提高了3倍。读这篇文章在火花2.0中详细的优化。
聪明:结构化流
火花流一直带领大数据空间的第一个系统统一批处理和流计算。当它流API,称为DStreams,是在火花0.7中引入的,它提供了开发人员和几个强大的属性:只有一次语义,在规模、容错强有力的保证一致性和高吞吐量。
然而,在处理数以百计的实际部署的火花,我们发现,应用程序需要实时决策往往需要不仅仅是一个流引擎。他们需要批堆栈深度集成和流堆栈,互动与外部存储系统,以及应对变化的能力的业务逻辑。因此,企业不仅仅要流引擎;相反,他们需要一个完整的堆栈,使他们能够开发端到端“连续应用。”
火花2.0解决这些用例通过一个名为结构化流的新API。与现有的流媒体系统相比,结构化流使三个关键的改进:
- 集成API与批处理作业。运行流计算,开发人员只需写一个批处理计算DataFrame /数据API,并自动火花incrementalizes计算运行它以流媒体的方式(即更新结果数据进来)。这种强大的设计意味着开发人员不必手工管理状态,失败,或与批处理作业保持应用程序同步。相反,流媒体的工作总是给出了相同的答案作为批处理作业相同的数据。
- 事务与存储系统的交互。结构化流处理引擎和容错性和一致性整体存储系统,使其易于编写的应用程序更新数据库用于服务生活,加入静态数据,或移动存储系统之间的数据可靠。
- 丰富的集成与火花。结构化流支持交互式流数据通过火花SQL查询,对静态数据连接,和已经在使用DataFrames许多图书馆,让开发人员构建完整的应用程序,而不只是流管道。在未来,期待更多的集成与MLlib和其他库。
火花2.0附带一个初始,alpha版本的结构化流,(小得惊人!)扩展DataFrame /数据API。这使它很容易采用现有火花实时用户想回答的新问题。其他重要的功能,包括支持基于事件时间的处理,无序/延迟数据,与非交互式查询,和交互数据来源和下沉。
我们也更新了砖的工作区来支持结构化流。例如,当启动一个流媒体查询,笔记本用户界面将自动显示其地位。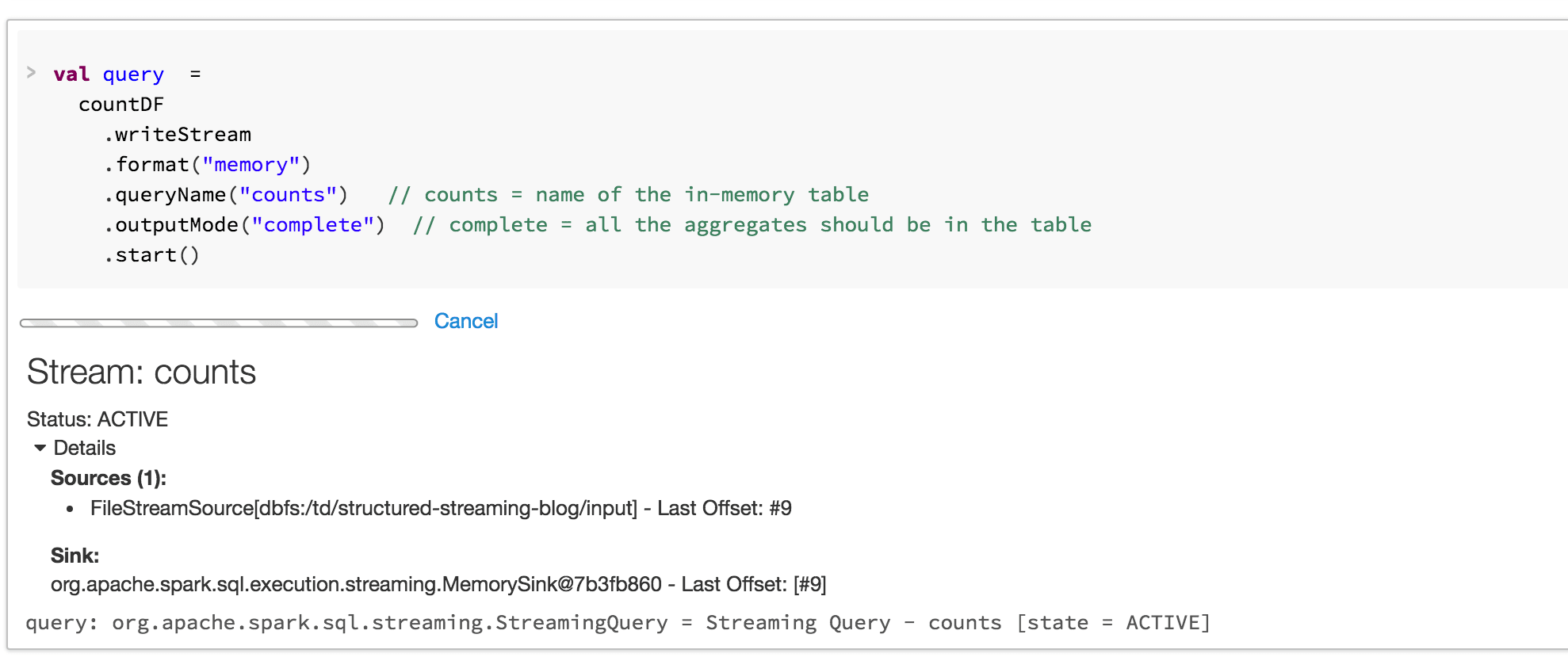
流媒体显然是一个广泛的话题,所以请继续关注一系列的博文结构化流在Apache 2.0火花的更多细节。
结论
引发用户最初来到Apache火花的易用性和性能。2.0双打在这些火花,同时支持一个更广泛的扩展它的工作负载。享受新版本在砖上。