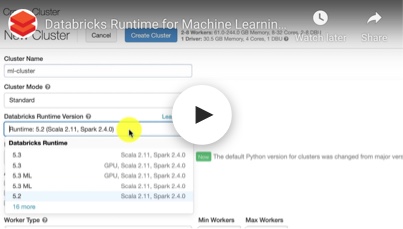
ML框架正在以疯狂的速度发展,从业者平均需要管理8个库。ML运行时提供了一键访问最流行的ML框架的可靠和性能分布,并通过预先构建的容器自定义ML环境。
Il ciclo di机器学习,dalla prepareazione dei dati all'inferenza, può essere accelerato con funzionalità di ML integration, fra cui sintonizazione degli iperparameter ricerca di modelli utilizzando Hyperopt e MLflow。
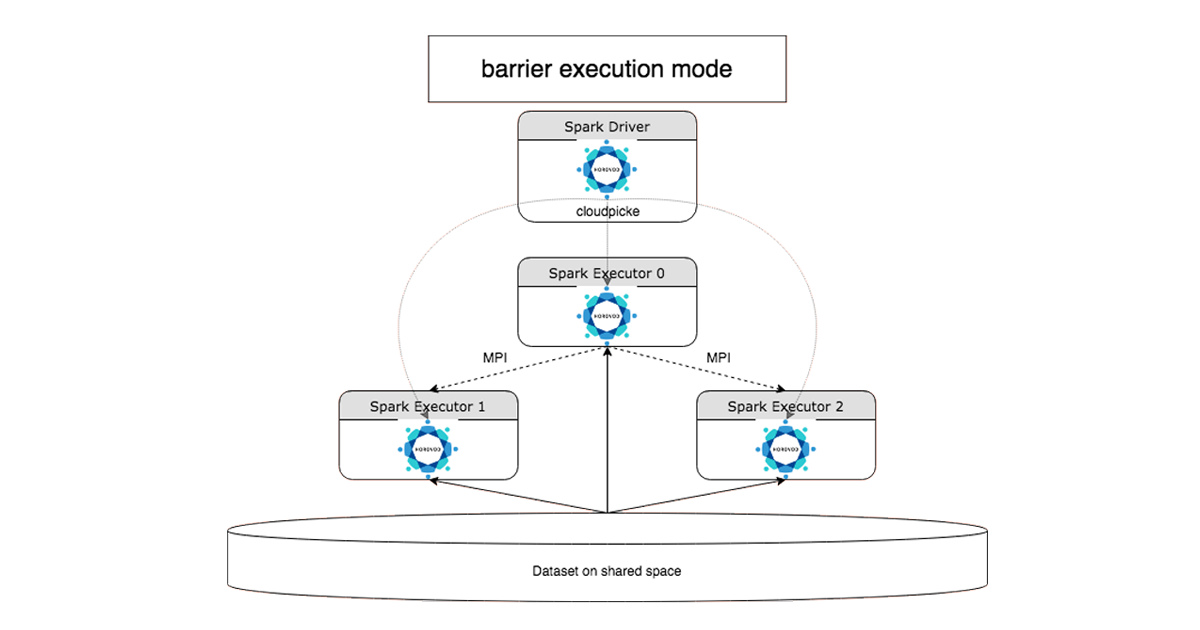
可扩展的大数据基础设施集群自动生成。机器学习运行时算法più diffusi e HorovodRunner,一个简单的API每个深度学习分发。
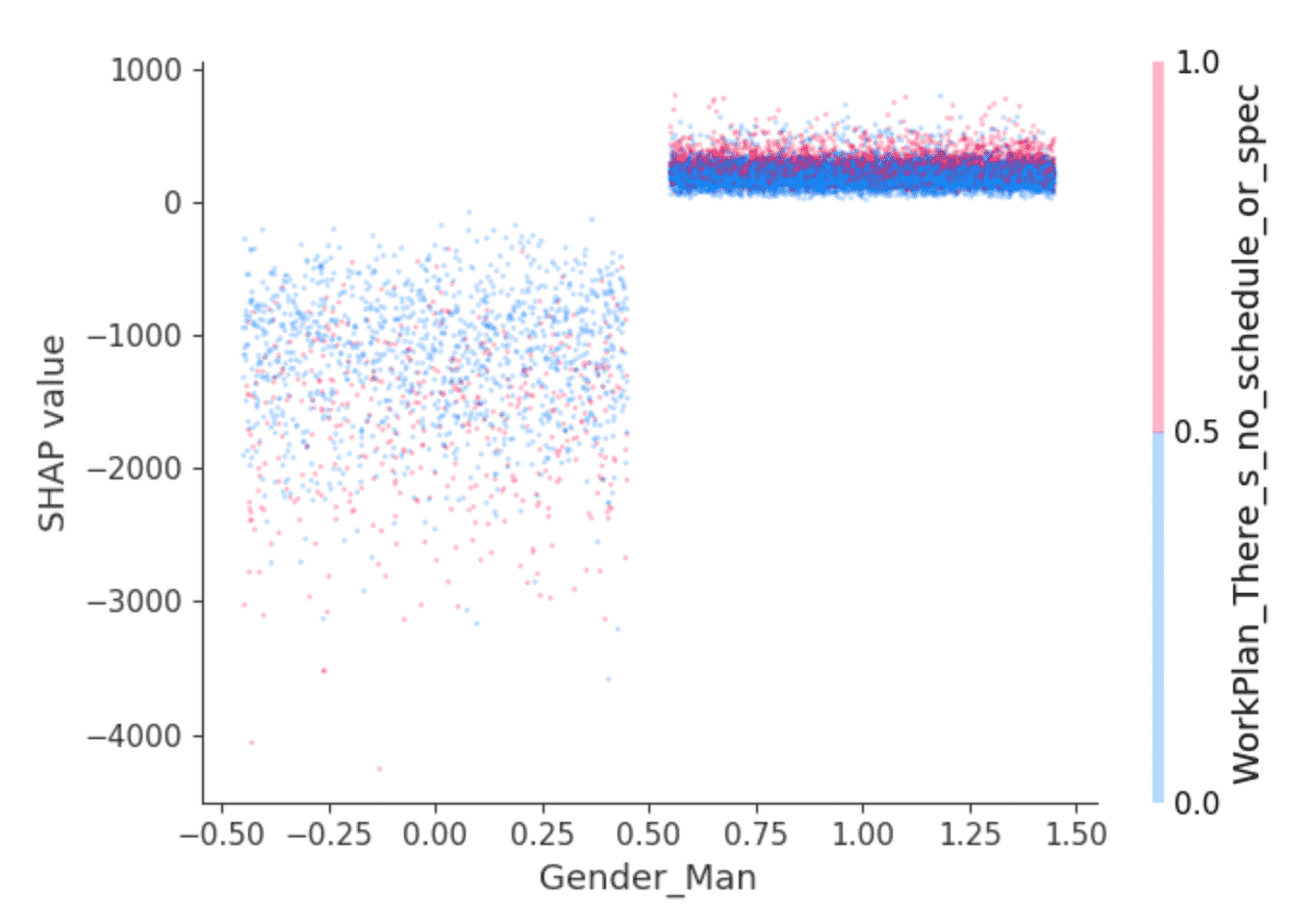
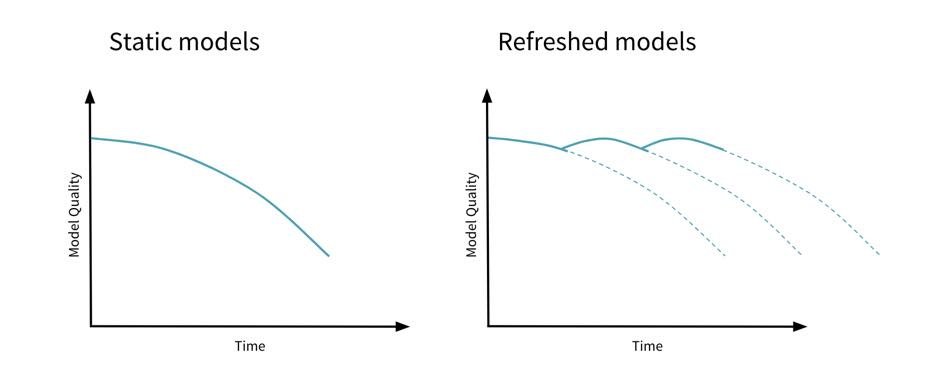
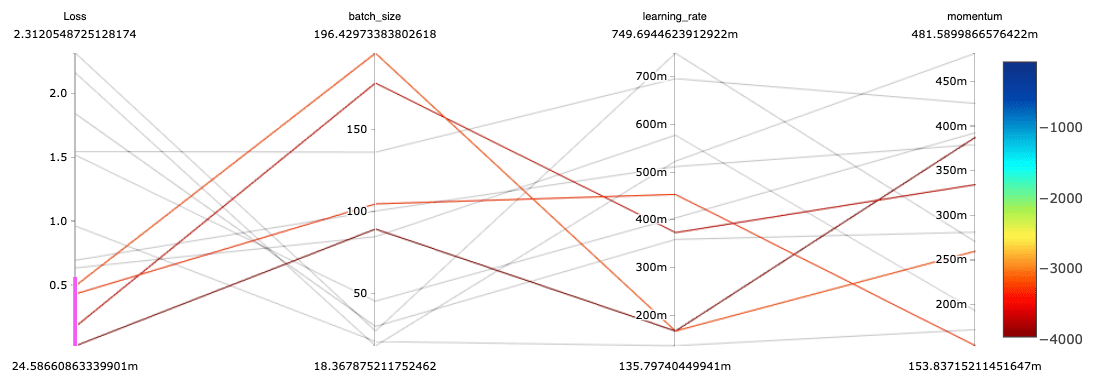
自动测量实验:tracciare,对抗e可视化centinaia di migliaia di实验方法利用MLflow开源o姿态图ela funzionalità平行di plottaggio delle坐标。
模型自动Ricerca(每毫升单结点):ricerca ottimizzata e distribution ita di perparameter condizionali su più architecture di modelli con Hyperopt avanzato e tracciamento automatico su MLflow。
自动参数化机器学习:ricerca ottimizzata e distribuita di perperparameter con Hyperopt avanzato e tracciamento automaticsu flow。
Sintonizzazione自动非参数机器学习分布:在MLflow中对PySpark MLlib进行交叉验证。
TensorFlow ottimizzato:TensorFlow ottimizzata / CUDA porta benefit in termini di prestazioni sui cluster GPU。
HorovodRunner:深度学习的一个nodo singolo的代码può essere迁移速度每girare su集群的数据,一个简单的API,一个复杂的问题,所有'uso di Horovod每一个'addestramento分布。
回归logistic MLlib ottimizzata e classificatorad albero:gli stimatori più diffusi sono stati ottimizzati nell'ambito di Databricks Runtime per ML, per frire un incremento della velocità fino al 40% rispetto ad Apache Spark 2.4.0。