自动优化Databricks
自动优化是一组可选的特性,在对Delta表进行单独写入时自动压缩小文件。自动优化会增加写操作的延迟开销,但会加速读操作。自动优化在以下场景中特别有用:
以分钟为单位的延迟是可以接受的流用例
合并成写三角洲湖的首选方法是什么创建表格作为选择或插入成都是常用操作
启用自动优化
在Databricks Runtime 9.1 LTS及以上版本中,以下操作默认启用优化写:
合并更新与子查询删除与子查询
对于其他操作,或者对于Databricks Runtime 7.3 LTS,您可以使用以下方法之一显式启用优化的写入和自动压缩:
新表:设置表属性
delta.autoOptimize.optimizeWrite=真正的而且delta.autoOptimize.autoCompact=真正的在创建表格命令。创建表格学生(idINT,的名字字符串,年龄INT)TBLPROPERTIES(δ.autoOptimize.optimizeWrite=真正的,δ.autoOptimize.autoCompact=真正的)
现有表:设置表属性
delta.autoOptimize.optimizeWrite=真正的而且delta.autoOptimize.autoCompact=真正的在改变表格命令。改变表格[table_name|δ.' <表格-路径>”]集TBLPROPERTIES(δ.autoOptimize.optimizeWrite=真正的,δ.autoOptimize.autoCompact=真正的)
所有新表:
集火花.砖.δ.属性.违约.autoOptimize.optimizeWrite=真正的;集火花.砖.δ.属性.违约.autoOptimize.autoCompact=真正的;
在Databricks Runtime 10.1及以上版本中,table属性delta.autoOptimize.autoCompact也接受值汽车而且遗产除了真正的而且假.当设置为汽车(推荐),Databricks调整目标文件大小以适合用例。当设置为遗产或真正的,自动压缩使用128mb作为目标文件大小。
此外,您可以通过配置为Spark会话启用和禁用这两个特性:
spark.databricks.delta.optimizeWrite.enabledspark.databricks.delta.autoCompact.enabled
会话配置优先于表属性,允许您更好地控制何时选择加入或退出这些特性。
什么时候加入,什么时候退出
本节提供关于何时选择加入和退出自动优化功能的指导。
何时选择进入优化的写入
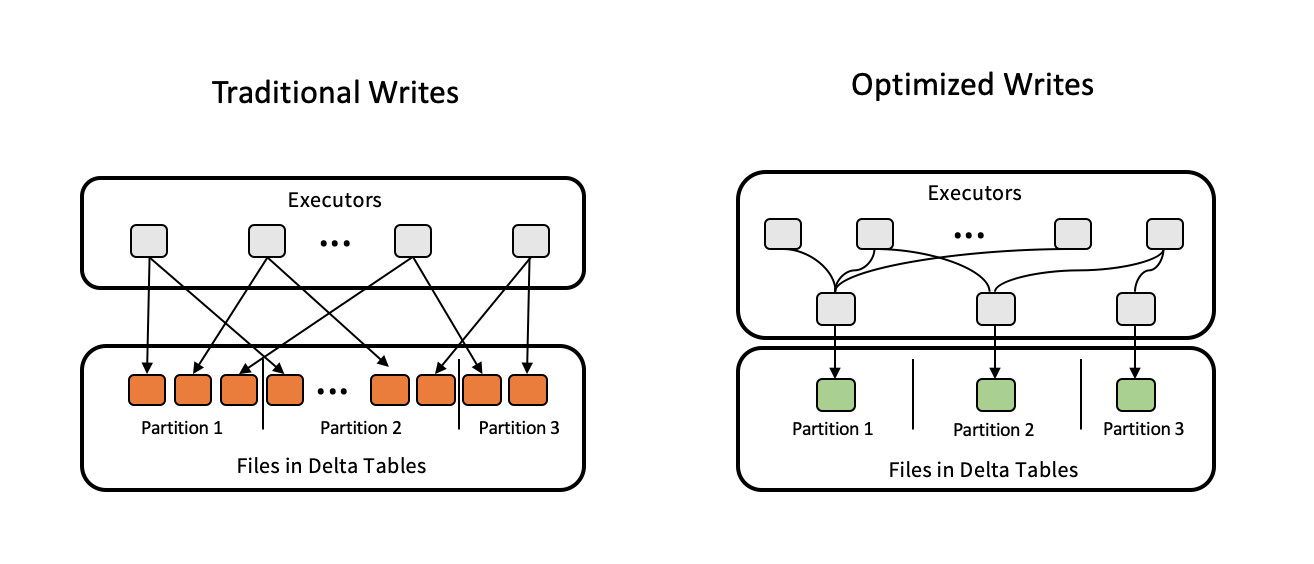
写优化的目的是使写入存储服务的数据吞吐量最大化。这可以通过减少写入的文件数量来实现,而不会牺牲太多的并行性。
优化的写操作要求根据目标表的分区结构对数据进行变换。这种洗牌自然会带来额外的成本。但是,写入期间的吞吐量增加可能会抵消shuffle的成本。如果不是,在查询数据时提高的吞吐量仍然值得使用该特性。
优化写的关键部分是它是一个自适应shuffle。如果您有一个流摄取用例,并且输入数据速率随时间变化,那么自适应shuffle将根据微批间的传入数据速率进行自我调整。如果你有代码片段合并(n)或重新分区(n)在您写入流之前,您可以删除这些行。
何时选择自动压缩
自动压缩发生在对表的写入成功之后,并在执行写入的集群上同步运行。这意味着如果您的代码模式是写入Delta Lake,然后立即调用优化,您可以删除优化如果启用自动压缩,则调用。
自动压缩使用不同的启发式优化.由于它在写入后同步运行,我们调优了自动压缩以使用以下属性运行:
Databricks不支持带有自动压缩的z - ordered,因为z - ordered比仅仅压缩要昂贵得多。
自动压缩生成的文件更小(128 MB)
优化(1 GB)。自动压缩会贪婪地选择一组最能利用压缩的有限分区。选择的分区数量将根据启动它的集群的大小而变化。如果您的集群有更多的cpu,就可以优化更多的分区。
控件可控制输出文件大小火花配置
spark.databricks.delta.autoCompact.maxFileSize.默认值为134217728,将大小设置为128 MB104857600设置文件大小为100MB。
示例工作流:并发删除或更新的流式摄取
这个工作流假设有一个集群运行24/7的流作业来摄取数据,还有一个集群每小时、每天或特别运行一次,以删除或更新一批记录。对于这个用例,Databricks建议您:
在表级启用优化的写操作
改变表格<table_name|δ.`table_path' >集TBLPROPERTIES(δ.autoOptimize.optimizeWrite=真正的)
这可以确保流写入的文件数量以及删除和更新作业的大小都是最佳的。
在执行删除或更新的作业上使用以下设置在会话级别上启用自动压缩。
火花.sql("set spark. databicks .delta. autocompact .enabled = true")
这允许文件在表中被压缩。由于它发生在删除或更新之后,因此可以降低事务冲突的风险。
常见问题(FAQ)
自动优化Z-Order文件?
自动优化只对小文件执行压缩。它没有z值文件。
自动优化损坏的Z-Ordered文件?
自动优化忽略Z-Ordered文件。它只压缩新文件。
如果我在我流进的表上启用了自动优化,并且并发事务与优化发生冲突,我的作业会失败吗?
不。导致自动优化失败的事务冲突将被忽略,流将继续正常运行。
我需要安排时间吗优化工作,如果自动优化是在我的表上启用?
对于大小大于10 TB的表,我们建议您保留优化在计划上运行,以进一步巩固文件,并减少Delta表的元数据。由于自动优化不支持z排序,您仍然应该调度优化...ZORDER通过定期运行的作业。
我有很多小文件。为什么自动优化不压缩他们?
默认情况下,auto optimization直到在一个目录中发现超过50个小文件才开始压缩。您可以通过设置更改此行为spark.databricks.delta.autoCompact.minNumFiles.拥有许多小文件并不总是一个问题,因为它可以导致更好的数据跳过,并且它可以帮助最小化合并和删除期间的重写。但是,有太多的小文件可能表明您的数据分区过度。