创建和运行数据砖的工作
本文详细介绍如何创建和运行数据砖工作使用UI。
为工作和学习配置选项如何编辑你的现有工作,明白了配置设置砖的工作。
学习如何管理和监控工作,明白了查看和管理工作。
创建您的第一个工作流与砖的工作,看到快速入门。
重要的
你只能创造就业数据科学与工程工作区或一个机器学习的工作区。
1000个并发任务工作空间是有限的。一个
429年太许多请求当你返回请求的响应不能立即开始运行。就业人数工作区可以创建在10000年一个小时是有限的(包括”提交”)。REST API创建的这个限制也会影响就业和笔记本工作流。
创建和运行工作使用CLI API,或者笔记本
学习使用砖CLI的创建和运行工作,明白了砖CLI。
学习使用工作API来创建和运行工作,明白了工作在REST API参考。
学习如何运行和调度工作直接在砖笔记本,看到的创建和管理计划的笔记本工作。
创建一个工作
做下列之一:
点击
 工作流在侧边栏,然后单击
工作流在侧边栏,然后单击 。
。在侧边栏中,单击
 新并选择工作。
新并选择工作。
的任务选项卡创建任务对话框出现。
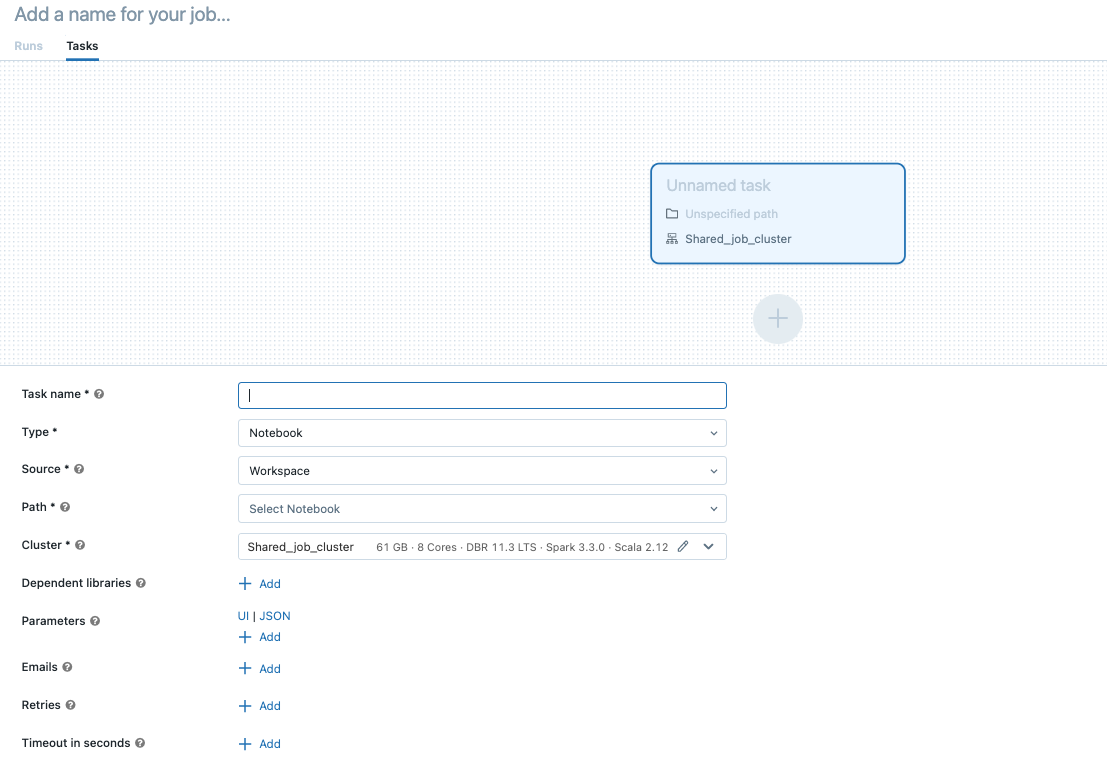
取代添加一个名称为你的工作…对你的工作名称。
输入一个名称的任务任务名称字段。
在类型下拉菜单中,选择任务运行的类型。看到任务类型的选择。
配置任务运行的集群。在集群下拉菜单,选择新工作的集群或现有通用的集群。
新工作的集群:点击编辑在集群下拉菜单并完成集群配置。
现有通用的集群:选择一个现有的集群中集群下拉菜单。在新页面中打开集群,单击
 图标右边的集群名称和描述。
图标右边的集群名称和描述。
了解更BOB低频彩多关于选择和配置集群运行任务,明白了使用砖计算你们的工作。
添加依赖库,点击+添加旁边依赖库。看到配置依赖库。
你可以为你的任务传递参数。每个任务类型有不同的要求,格式和传递参数。
笔记本:点击添加并指定每个参数的键和值传递给任务。你可以覆盖或添加额外的参数手动运行一个任务使用用不同的参数运行工作选择。参数设置的值笔记本电脑部件指定的关键参数。使用任务参数变量通过一组有限的动态值作为参数值的一部分。
JAR:使用json格式的字符串来指定参数的数组。这些字符串作为参数传递给主类的主要方法。看到配置罐工作参数。
火花提交任务:参数指定为一个json格式的字符串数组。符合Apache火花spark-submit惯例,参数在JAR的路径传递给主类的主要方法。
Python脚本:使用json格式的字符串来指定参数的数组。这些字符串作为参数传递,可以解析使用argparse在Python模块。
Python轮:在参数下拉菜单,选择位置参数输入参数作为json格式的字符串数组,或选择关键字参数>添加进入每个参数的键和值。这两个位置参数和关键字参数都作为命令行参数传递给Python轮任务。
为任务开始有选择地接收通知,成功,或失败,点击+添加旁边电子邮件。通知发送初始任务失败和任何后续重试。
可选配置重试策略的任务,点击+添加旁边重试。看到配置重试策略。
可选配置的超时任务,点击+添加旁边在几秒钟内超时。看到为一个任务配置超时。
点击创建。
 。
。
 图标右边的集群名称和描述。
图标右边的集群名称和描述。创建第一个任务后,您可以配置工作水平设置,如通知、工作触发器和权限。看到编辑的工作。
添加另一个任务,点击 在DAG视图中。一个共享的集群选项如果您配置了一个提供新工作的集群前一个任务。您还可以配置一个集群为每个任务当您创建或编辑一个任务。了解更BOB低频彩多关于选择和配置集群运行任务,明白了使用砖计算你们的工作。
在DAG视图中。一个共享的集群选项如果您配置了一个提供新工作的集群前一个任务。您还可以配置一个集群为每个任务当您创建或编辑一个任务。了解更BOB低频彩多关于选择和配置集群运行任务,明白了使用砖计算你们的工作。
任务类型的选择
以下是可以添加到你的砖工作任务类型和可用的选项不同的任务类型:
笔记本:在源下拉菜单,选择一个笔记本的位置;要么工作空间对于一个笔记本或位于一个砖工作区文件夹Git提供者笔记本位于一个偏远的Git存储库。
工作空间:使用文件浏览器找到笔记本,点击笔记本名称,点击确认。
Git提供者:点击编辑并输入Git存储库信息。看到用笔记本从远程Git存储库。
请注意
笔记本电池总产量(合并后输出的笔记本电池)20 mb的大小限制。此外,单个细胞输出8 mb大小限制。如果电池总产量超过20 mb,或者单个细胞的输出大于8 mb,运行是取消,标记为失败。
如果你需要帮助找到细胞接近或超出了限制,笔记本和一个通用的集群运行和使用笔记本自动保存技术。
JAR:指定主类。使用类的完全限定名称包含的主要方法,例如,
org.apache.spark.examples.SparkPi。然后单击添加下依赖库添加库才能运行这个任务。这些库必须包含主类之一。了解更BOB低频彩多关于JAR任务,明白了用一罐砖的工作。
火花提交:在参数文本框,指定主类,库JAR的路径,和所有参数,格式化为JSON字符串的数组。下面的示例配置spark-submit任务运行
DFSReadWriteTest从Apache火花的例子:(”——阶级”,“org.apache.spark.examples.DFSReadWriteTest”,“dbfs: / FileStore /图书馆/ spark_examples_2_12_3_1_1.jar”,“/ dbfs / databricks-datasets / README.md”,“/ FileStore / /输出例子/”]
Python脚本:在源下拉,选择一个Python脚本的位置工作空间脚本在本地工作区,DBFS脚本位于DBFS,或Git提供者脚本位于一个Git仓库。在路径文本框中,输入Python脚本的路径:
工作空间:在选择Python文件并单击对话框中,浏览到Python脚本确认。必须在您的脚本砖回购。
DBFS:输入一个Python脚本的URI DBFS和云存储;例如,
dbfs: / FileStore / myscript.py。Git提供者:点击编辑并输入Git存储库信息。看到使用Python代码从一个远程Git存储库。
三角洲生活表管道:在管道下拉菜单,选择一个已存在的三角洲生活表管道。
重要的
你只可以使用管道的触发管道的任务。不支持连续管道的工作任务。更多地BOB低频彩了解和连续管道引起的,看到的连续与管道执行触发。
Python轮:在包名文本框,输入包导入,例如,
mywheel - 1.0 - py2.py3 any.whl——没有。在入口点文本框中,输入函数调用时开始。点击添加下依赖库添加库才能运行这个任务。SQL:在SQL任务下拉菜单,选择查询,指示板,警报,或文件。
请注意
的SQLSQL和任务需要砖serverless或支持SQL仓库。
查询:在SQL查询下拉菜单中,选择查询时所执行的任务。
指示板:在SQL仪表板下拉菜单,选择一个仪表盘更新任务运行时。
警报:在SQL警告下拉菜单中,选择警报触发进行评估。
文件:在源下拉菜单,选择Git提供者,点击编辑或添加一个git参考Git存储库,并输入细节。看到从一个远程Git存储库使用SQL查询。
在SQL仓库下拉菜单,选择一个serverless或支持SQL仓库运行的任务。
印度生物技术部:看在砖使用印度生物技术部转换工作对于一个详细示例如何配置一个印度生物技术部的任务。
 接下来的任务路径复制路径到剪贴板。
接下来的任务路径复制路径到剪贴板。 并选择克隆的任务。
并选择克隆的任务。运行工作
点击
工作流在侧边栏。选择一份工作并单击运行选项卡。您可以运行工作运行后立即或调度的工作。
如果一个或多个任务的工作与多个任务不成功,您可以重新运行失败的任务的一部分。看到重新运行失败,跳过任务。
 。
。运行一个服务主体的工作
预览
这个特性是在公共预览。
默认情况下,工作作为工作的主人的身份运行。这意味着工作假设工作的所有者的权限。这项工作只能访问数据和砖工作所有者权限访问的对象。你可以改变身份,工作运行服务主体。然后,假设工作服务主体的权限,而不是所有者。工作区管理员的身份也可以改变到另一个用户运行的工作是在工作区中。
改变运行设置你需要的可以管理或是老板工作许可。用户可以设置工作区运行设置为自己或任何服务主体在工作区中,他们有服务主体的用户的角色。工作区管理员可以设置运行设置任何工作区用户或任何服务主体在工作区中,他们有服务主体的用户的角色。有关更多信息,请参见用于管理服务主体的角色和工作访问控制。
改变运行领域,请执行以下操作:
在侧边栏中,单击
工作流。在的名字列,单击工作名称。
在工作细节侧板,点击旁边的铅笔图标运行字段。
搜索和选择服务主体。
点击保存。
您还可以列出你的服务主体用户使用工作空间层SCIM API的角色。有关更多信息,请参见列出可以使用的服务主体。
运行安排一份工作
您可以使用一个安排在指定的时间自动运行砖的工作和时间。看到添加一个工作进度表。
运行一个连续工作
你可以确保你的工作总是有一个活跃的运行。看到运行一个连续工作。
当得到新的文件运行工作
触发工作运行当新的文件到一个外部位置,使用文件到达触发。