

建立一个网络安全Lakehouse CrowdStrike猎鹰事件







2021年5月20日 在bob体育客户端下载平台的博客
现在开始你自己的砖部署和运行这些笔记本电脑。
端点数据安全团队所需的威胁检测,威胁狩猎,事故调查和满足合规要求。数据量可以tb每天或每年pb。大多数组织难以收集、存储和分析端点日志,因为与这些大量数据相关联的成本和复杂性。但这并不一定是这样。
在这两个部分博客系列,我们将讨论如何实施pb级的端点数据与砖与高级分析改善安全状况,以成本有效的方式。本博客)(第1部分将涵盖数据收集和集成的体系结构与SIEM (Splunk)。年底这个博客提供笔记本电脑你可以使用数据进行分析。第2部分将讨论特定的用例,如何创建毫升模型和自动化的充实和分析。在第2部分,您将能够实现检测和调查威胁的笔记本使用终点数据。
我们将使用Crowdstrike的猎鹰日志我们的例子。访问猎鹰日志,可以使用“猎鹰”数据复制因子(罗斯福)将原始事件数据从CrowdStrike Amazon S3等云存储平台。bob体育客户端下载这些数据可摄入、转换、分析和存储使用砖Lakehouse平台与其他安全遥测。bob体育客户端下载客户可以摄取CrowdStrike猎鹰数据,应用面向实时检测,与砖SQL的搜索历史数据,查询从SIEM工具如Splunk Splunk砖插件。
Crowdstrike实施数据的挑战
尽管Crowdstrike猎鹰数据提供全面的事件日志记录的细节,这是一个艰巨的任务来摄取,流程和实施复杂,大量的网络安全数据实时基础上符合成本效益的方式。这些都是一些著名的挑战:
- 实时数据摄入规模:很难跟踪处理和未经处理的原始数据文件,由罗斯福写在近乎实时的云存储。
- 复杂的转换:格式是半结构化的数据。每个日志文件的每一行包含数百个underministically不同类型的负载,和事件数据的结构可以随时间变化的。
- 数据治理:这种类型的数据可以敏感,必须封闭和访问只需要它的用户。
- 简化安全分析端到端:可伸缩的工具都需要做数据工程,MLand分析这些快速和高容量的数据集。
- 合作:有效的协作可以利用专业知识从数据工程师、网络安全分析师和ML工程师。因此,拥有一个协作的平台提高网络安全分析的效率和响应工作负bob体育客户端下载载。
因此,安全工程师在企业发现自己在一个困难的情况下努力管理成本和运营效率。他们要么不得不接受被锁到非常昂贵的专有系统或花费巨大的努力建立自己的端点安全工具而争取可伸缩性和性能。
砖网络安全lakehouse
砖提供安全团队和数据科学家的一个新的希望有效地执行他们的工作,以及一套工具来应对不断增长的大数据挑战和复杂的威胁。
Lakehouse,一个开放的体系结构,结合湖泊和数据仓库数据的最佳元素,简化了构建一种数据工程管道逐步增加了结构的数据。一种架构的好处是数据工程师可以建造管道,始于原始数据作为“单一来源的真相”的所有流动。Crowstrike半结构化的原始数据可以存储多年,和随后的转换和聚合可以做在一个端到端的流媒体方式提炼数据,引入上下文特定的结构分析和检测安全风险在不同的场景中。
- 数据摄取:自动装卸机(AWS|Azure|GCP)帮助立即读取数据尽快编写一个新文件Crowdstrike罗斯福到原始数据存储。它利用云通知服务逐步过程到达云的新文件。自动装卸机也自动配置和听新文件和通知服务可以扩大每秒数以百万计的文件。
- 统一的流和批处理:三角洲湖是一个开放的方法将数据管理和数据治理湖泊,利用Apache火花的™分布式计算大量的数据和元数据。砖的三角洲引擎是一个高度优化的引擎,每秒可以处理数百万条记录。
- 数据治理:与砖表访问控制(AWS|Azure|GCP),管理员可以授予不同级别的访问权限三角洲表根据用户的业务功能。
- 安全分析工具:砖的SQL有助于创建一个交互式仪表板与自动报警当检测到不寻常的模式。同样,它可以很容易地集成highly-adopted BI工具如表、微软权力BI和美人。
- 砖笔记本的合作:砖协作笔记本启用安全团队合作。多个用户可以在多种语言中运行查询,共享可视化,使评论在同一个工作区没有打扰的继续调查。
Lakehouse Crowdstrike猎鹰数据架构
我们建议以下lakehouse网络安全架构的工作负载,比如Crowdstrike猎鹰数据。自动装卸机和三角洲湖简化从云存储读取原始数据的过程和写作以低成本和最小DevOps三角洲表工作。
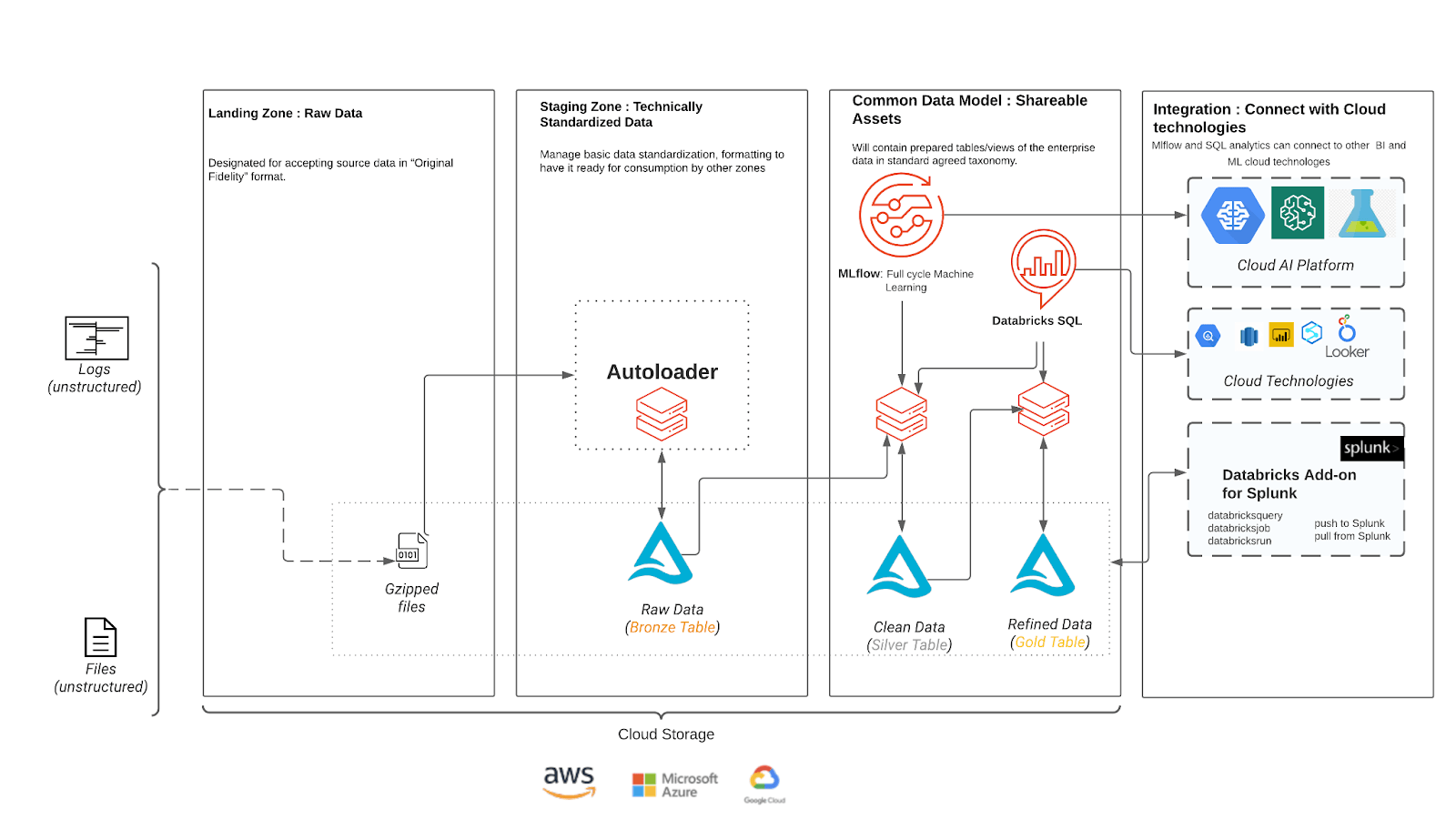
在此体系结构中,半结构化Crowdstrike数据加载到客户的云存储在着陆区。然后自动装卸机使用云服务通知自动触发新文件的处理和摄入到客户的青铜表,这将作为真理的单一来源为所有下游工作。自动装卸机将跟踪和加工使用检查点文件,以防止重复的数据处理。
当我们从bronze-to-silver阶段,模式将被添加到提供的数据结构。因为我们正在阅读单一来源的真理,我们能够处理所有不同的事件类型和实施正确的模式写各自的表。在银层的能力执行模式提供了一个坚实的基础来构建毫升和分析工作量。
的黄金阶段,总量数据更快的查询和性能在仪表盘和BI工具,是可选的,根据用例和数据量。警报可以设置触发当意想不到的趋势。
另一个可选的特性砖的附加Splunk,它允许安全团队利用砖的成本效益模型和人工智能的力量,而无需离开Splunk的舒适。客户可以从内部运行专用查询数据砖Splunk仪表板或搜索栏插件。用户还可以在砖推出笔记本或者工作通过Splunk仪表板或响应Splunk搜索。砖集成是双向的,让客户总结嘈杂的数据或运行检测出现在Splunk企业安全的砖。顾客甚至可以运行Splunk搜索从砖笔记本,防止重复数据的需要。
Splunk和砖集成允许客户降低成本,扩大数据来源分析,提供一种更健壮的分析引擎的结果,没有改变员工日常使用的工具。
代码走查
自动装卸机摘要以来最复杂的基于文件的数据摄入的一部分,raw-to-bronze摄入管道可以创建几行代码。下面是一个Scala代码示例三角洲摄入管道。Crowdstrike猎鹰事件记录有一个共同的字段名:“event_simpleName。”
val crowdstrikeStream = spark.readStream.format (“cloudFiles”).option (“cloudFiles.format”,“文本”)/ /文本文件不需要模式.option (“cloudFiles.region”,“us-west-2”).option (“cloudFiles.useNotifications”,“真正的”).load (rawDataSource).withColumn (“load_timestamp”current_timestamp ()).withColumn (“load_date”to_date(美元)“load_timestamp”)).withColumn (“eventType”from_json(美元)“价值”,“结构”,地图空虚(字符串,字符串])).selectExpr (“eventType.event_simpleName”,“load_date”,“load_timestamp”,“价值”).writeStream.format (“δ”).option (“checkpointLocation”checkPointLocation).table (“demo_bronze.crowdstrike”)在raw-to-bronze层,只有事件叫从原始数据中提取。通过添加一个负载日期和时间戳列,用户原始数据存储到铜表。铜表分区的事件名称和装载日期,这有助于使bronze-to-silver工作更好的性能,特别是当兴趣有限数量的事件日期范围。
接下来,bronze-to-silver流工作从一个青铜表读取事件,执行模式和写几百个事件表基于事件的名称。下面是一个Scala代码示例:
火花.readStream.option (“ignoreChanges”,“真正的”).option (“maxBytesPerTrigger”、“2 g”).option (“maxFilesPerTrigger”、“64”).format(“δ”).load (bronzeTableLocation)。过滤器(美元“event_simpleName”===“event_name”)from_json .withColumn(“事件”(“价值”美元,schema_of_json (sampleJson)))。选择($”事件。*”、“load_timestamp”,“美元load_date”).withColumn (“silver_timestamp”,current_timestamp()).writeStream.format(“δ”).outputMode(“追加”).option (“mergeSchema”,“真正的”).option (“checkpointLocation检查点)tableLocation .option(“路径”)。开始()每个事件模式可以存储在一个注册中心或在三角洲表模式需要跨多个数据驱动的共享服务。请注意,上面的代码使用了一个示例json字符串从青铜读取表,和推断从json使用的模式schema_of_json()。之后,使用json字符串转换为一个结构体from_json()。然后,struct夷为平地,促使添加一个时间戳列。这些步骤提供一个与所需的所有列dataframe附加到事件表。最后,我们把这个结构化数据用附加到事件表模式。
也可以扇出事件与一个流与多个表foreachBatch通过定义一个函数,它将处理microbatches。使用foreachBatch(),可以重用现有的过滤和批处理数据源编写多个表。然而,foreachBatch()只提供“至少一次”写担保。所以,需要手动实现执行仅一次语义。
在这个阶段,任何的结构化数据可以查询语言支持砖笔记本和工作:Python, R, Scala和SQL。毫升的银层数据方便使用和网络攻击分析。
下一个流管道将白银和黄金。在这个阶段,可以聚合数据仪表盘和报警。在这个博客系列的第二部分中我们将提供更多的洞察如何使用砖SQL构建仪表盘。
接下来是什么
请继续关注更多的博文,构建更重视这个用例通过应用毫升和使用砖SQL。
您可以使用这些笔记本电脑在你自己的砖部署。每个部分笔记本的评论。我们邀请你的电子邮件(电子邮件保护)。我们期待着您的问题和建议,使这个笔记本更容易理解和部署。
现在,我们邀请您登录到自己的砖和运行这些笔记本电脑。我们期待你的反馈和建议。
详细请参考文档说明进口要运行的笔记本。
确认
我们要感谢Bricksters谁支持这个博客,并特别感谢Monzy Merza,安德鲁•哈钦森Anand Ladda深刻的讨论和贡献。