培训和收敛性
大多数人工智能和机器学习的重要组成部分是循环的,即系统在许多迭代改进的训练。一个非常简单的方法来训练以这种方式只是在for循环执行更新。我们看到一个这样的例子在第二课:
进口tensorflow tf x =特遣部队。变量(0,name = ' x ') = tf.global_variables_initializer模型与tf.Session()()如会话:因为我在范围(5):session.run(模型)x = x + 1打印(session.run (x))我们可以改变这个工作流而不是使用一个变量作为收敛循环,如以下:
进口tensorflow tf x = tf.Variable (0。name = ' x ')阈值= tf.constant(5)模型= tf.global_variables_initializer与tf.Session()()如会话:session.run(模型),而session.run (tf.less (x,阈值)):x = x + 1 x_value = session.run (x)打印(x_value)这里的主要变化是,现在是一个循环而循环,继续循环测试(使用tf.lessless-than-test)是正确的。在这里,我们测试x小于给定的阈值(存储在一个常数),如果是这样,我们继续循环。
梯度下降法
任何机器学习库必须有一个梯度下降算法。我认为这是一个法律。无论如何,Tensorflow有几个不同的主题,他们是有相当的直接使用。
梯度下降学习算法,试图减少一些错误。你问什么错误?这是我们,尽管有一些常用的方法。
让我们先从一个基本的例子:
进口tensorflow一样tf进口numpy np # x和y是占位符我们训练数据x = tf.placeholder(“浮动”)y = tf.placeholder(“浮动”)# w是变量存储我们的价值观。它是初始化开始“猜测”# w[0]是我们的“a”方程,w[1]是“b”w = tf.Variable ([1.0, 2.0], name = " w ") #我们的模型的y = x * + b y_model =特遣部队。乘(x, w [0]) + w[1] #我们的错误被定义为不同误差的平方=特遣部队。广场(y - y_model) #梯度下降优化器的重担train_op = tf.train.GradientDescentOptimizer (0.01) .minimize(错误)#正常TensorFlow -初始化值,创建一个会话模型和运行模式= tf.global_variables_initializer与tf.Session()()如会话:session.run(模型),因为我在范围(1000):x_value = np.random.rand () y_value = x_value * 2 + 6 session.run (train_op feed_dict = {x: x_value y: y_value}) w_value = session.run (w)打印(“预测模型:{:。3 f} x + {b: .3f}”。格式(a = w_value [0], b = w_value [1]))这是主要的兴趣train_op = tf.train.GradientDescentOptimizer (0.01) .minimize(错误)培训步骤是定义的地方。它的目标是减少的价值错误变量,这是前面定义的平方差异(一种常见的误差函数)。的0.01步骤需要努力学习更好的价值。
这里一个重要的注意是我们优化只是一个单一值,但是这个值可以是一个数组。这就是为什么我们使用w变量,而不是两个独立的变量一个和b。
其他优化
TensorFlow一系列类型的优化,和有能力来定义您自己的(如果你是成之类的)。我们如何使用它们的API,看到这个页面。列出的是:
- GradientDescentOptimizer
- AdagradOptimizer
- MomentumOptimizer
- AdamOptimizer
- FtrlOptimizer
- RMSPropOptimizer
其他优化方法TensorFlow可能在将来的版本中出现,或在第三方代码。说,上述优化要满足最深度学习技术。如果你不确定使用哪一种使用GradientDescentOptimizer除非是失败。
策划的错误
我们可以画出错误每次迭代后得到以下输出:
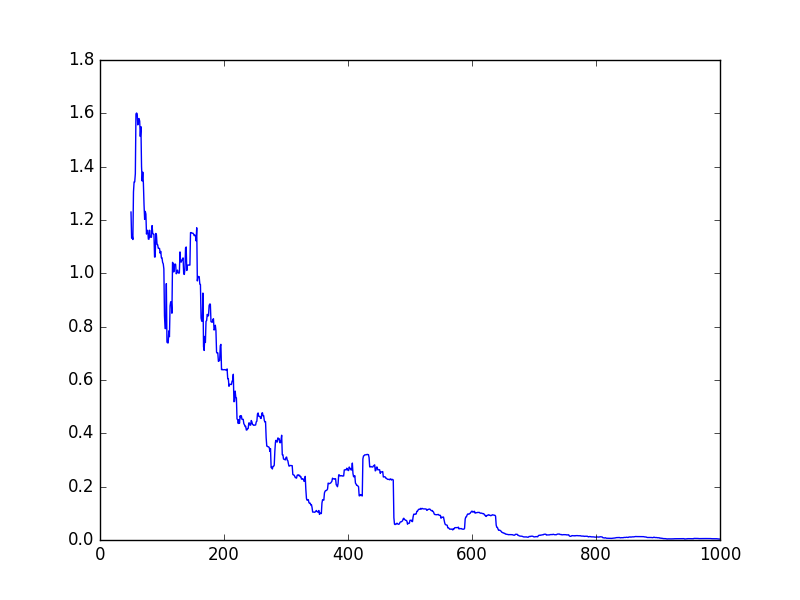
这是一个小改变的代码。首先,我们创建一个表来存储错误。然后,循环内部,我们显式计算train_op和错误。我们做这一行,所以这个错误只计算一次。如果我们这么做是单独的行,它将计算错误,然后训练步骤,这样做,它将需要再计算错误。
下面我把下面的代码只是为了tf.global_variables_initializer ()线从之前的计划——这条线以上的一切都是相同的。
与tf.Session错误=[]()届:session.run(模型)在范围(1000):我x_train = tf.random_normal((1),意味着= 5,stddev = 2.0) y_train = x_train * 2 + 6 x_value y_value = session.run ([x_train, y_train]) _, error_value = session.run (train_op、错误,feed_dict = {x: x_value y: y_value}) errors.append (error_value) w_value = session.run (w)打印(“预测模型:{:。3 f} x + {b: .3f}”。格式(a = w_value [0], b = w_value[1]))进口matplotlib。pyplot plt plt.plot ([np.mean(错误[i-50:我])我的范围(len(错误))])plt.show () plt.savefig (“errors.png”)您可能已经注意到,我把窗口的平均水平——使用np.mean(错误(i-50:我))而不是使用错误(我)。这样做的原因是,我们只做一个测试循环,因此,虽然错误往往减少,反射在不少。在这个窗口的平均平滑一点,但你可以在上面看到的,它仍然跳来跳去。
1)创建一个收敛函数k - means第六课的例子,停止训练如果质心和新老质心之间的距离小于一个给定的ε值。
2)尝试分离一个和b值梯度下降(在示例w使用)。
3)我们的示例火车上只是一个例子,这是低效的。扩展它来学习使用数量(50)的训练样本。
