Apache火花
回到术语表什么是Apache Spark?
Apache Spark是一个用于大数bob下载地址据工作负载的开源分析引擎。它可以处理批处理以及实时分析和数据处理工作负载。Apache Spark始于2009年,当时是加州大学伯克利分校的一个研究项目。研究人员正在寻找一种方法来加快处理工作Hadoop系统。它是基于Hadoop的MapReduce它扩展了MapReduce模型,有效地将其用于更多类型的计算,其中包括交互式查询和流处理。Spark为Java、Scala、Python和R编程语言提供了本地绑定。此外,它还包括几个库来支持构建机器学习[MLlib]、流处理[Spark Streaming]和图形处理[GraphX]的应用程序。Apache Spark由Spark Core和一组库组成。Spark Core是Apache Spark的核心,负责提供分布式任务传输、调度和I/O功能。Spark Core引擎使用弹性分布式数据集(RDD)的概念作为其基本数据类型。RDD的设计使它对用户隐藏了大部分的计算复杂性。Spark对数据的操作方式是智能的;数据和分区在服务器集群中聚合,然后可以在服务器集群中计算数据,并将其移动到不同的数据存储或通过分析模型运行。您不会被要求指定文件的目的地或存储或检索文件所需的计算资源。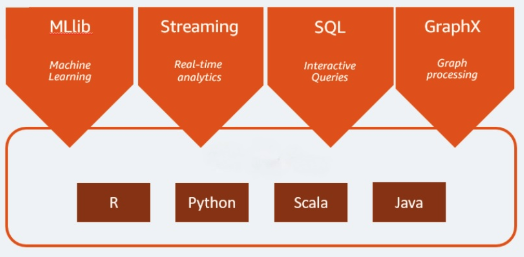
Apache Spark的好处是什么?
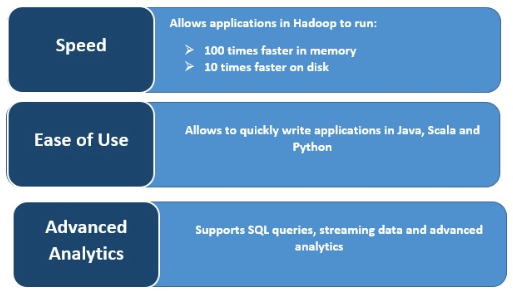
速度
Spark通过跨多个并行操作在内存中缓存数据来执行非常快。Spark的主要特点是它的内存引擎可以提高处理速度;在内存中处理时比MapReduce快100倍,在磁盘上处理大规模数据时比MapReduce快10倍。Spark通过减少对磁盘操作的读写数量来实现这一点。实时流处理
Apache Spark可以处理实时流以及其他框架的集成。Spark以小批量的方式接收数据,并对这些小批量的数据执行RDD转换。支持多工作负载
Apache Spark可以运行多种工作负载,包括交互式查询、实时分析、机器学习和图形处理。一个应用程序可以无缝地组合多个工作负载。增加可用性
支持多种编程语言的能力使其具有动态性。它允许你快速地用Java、Scala、Python和R编写应用程序;为构建应用程序提供了多种语言。先进的分析
Spark支持SQL查询、机器学习、流处理和图形处理。额外的资源
回到术语表
