机器学习模型
回到术语表
什么是机器学习模型?
机器学习模型是一种程序,可以从以前未见过的数据集中发现模式或做出决定。例如,在自然语言处理中,机器学习模型可以解析并正确识别之前从未听过的句子或单词组合背后的意图。在图像识别中,可以教机器学习模型识别物体,如汽车或狗。机器学习模型可以通过使用大型数据集进行“训练”来执行这些任务。在训练过程中,机器学习算法被优化,以根据任务从数据集中找到特定的模式或输出。这个过程的输出——通常是一个具有特定规则和数据结构的计算机程序——被称为机器学习模型。什么是机器学习算法?
机器学习算法是一种在一组数据中寻找模式的数学方法。机器学习算法通常来自统计学、微积分和线性代数。机器学习算法的一些流行示例包括线性回归、决策树、随机森林和XGBoost。什么是机器学习中的模型训练?
在数据集(称为训练数据)上运行机器学习算法并优化算法以找到特定模式或输出的过程称为模型训练。得到的具有规则和数据结构的函数称为经过训练的机器学习模型。机器学习有哪些不同类型?
一般来说,大多数机器学习技术可以分为监督学习、无监督学习和强化学习。什么是监督式机器学习?
在监督机器学习中,算法被提供一个输入数据集,并被奖励或优化以满足一组特定的输出。例如,监督机器学习广泛应用于图像识别,利用一种称为分类的技术。有监督的机器学习也用于预测人口统计数据,如人口增长或健康指标,利用一种称为回归的技术。什么是无监督机器学习?
在无监督机器学习中,算法被提供一个输入数据集,但没有奖励或优化到特定的输出,而是根据共同特征对对象进行分组。例如,在线商店的推荐引擎依赖于无监督机器学习,特别是一种称为聚类的技术。什么是强化学习?
在强化学习中,算法通过多次试错实验进行自我训练。强化学习发生在算法与环境持续交互时,而不是依赖于训练数据。强化学习最流行的例子之一是自动驾驶。有哪些不同的机器学习模型?
机器学习模型有很多,几乎所有的模型都是基于特定的机器学习算法。流行的分类和回归算法属于监督机器学习,聚类算法通常部署在无监督机器学习场景中。监督式机器学习
- 逻辑回归:逻辑回归用于确定输入是否属于某个组
- 支持向量机(SVM):支持向量机为n维空间中的每个对象创建坐标,并使用超平面根据共同特征对对象进行分组
- 朴素贝叶斯:朴素贝叶斯是一种假设变量之间独立的算法,并根据特征使用概率对对象进行分类
- 决策树:决策树也是分类器,用于通过遍历树的叶子和节点来确定输入属于什么类别
- 线性回归:线性回归用于识别感兴趣的变量与输入变量之间的关系,并根据输入变量的值预测其值。
- kNN: k个最近邻技术涉及对数据集中最接近的对象进行分组,并在对象中找到最频繁或平均的特征。
- 随机森林:随机森林是来自随机数据子集的许多决策树的集合,导致树的组合可能比单个决策树更准确地预测。
- Boosting算法:Boosting算法,如Gradient Boosting Machine, XGBoost, LightGBM,使用集成学习。它们结合了来自多个算法(如决策树)的预测,同时考虑了来自前一个算法的错误。
无监督机器学习
- K- means: K- means算法查找对象之间的相似性,并将它们分组到K个不同的簇中。
- 分层聚类:分层聚类构建嵌套集群的树,而不必指定集群的数量。
什么是机器学习中的决策树?
决策树是ML中的一种预测方法,用于确定对象属于哪个类。顾名思义,决策树是一种树状的流程图,其中对象的类别是使用某些已知条件逐步确定的。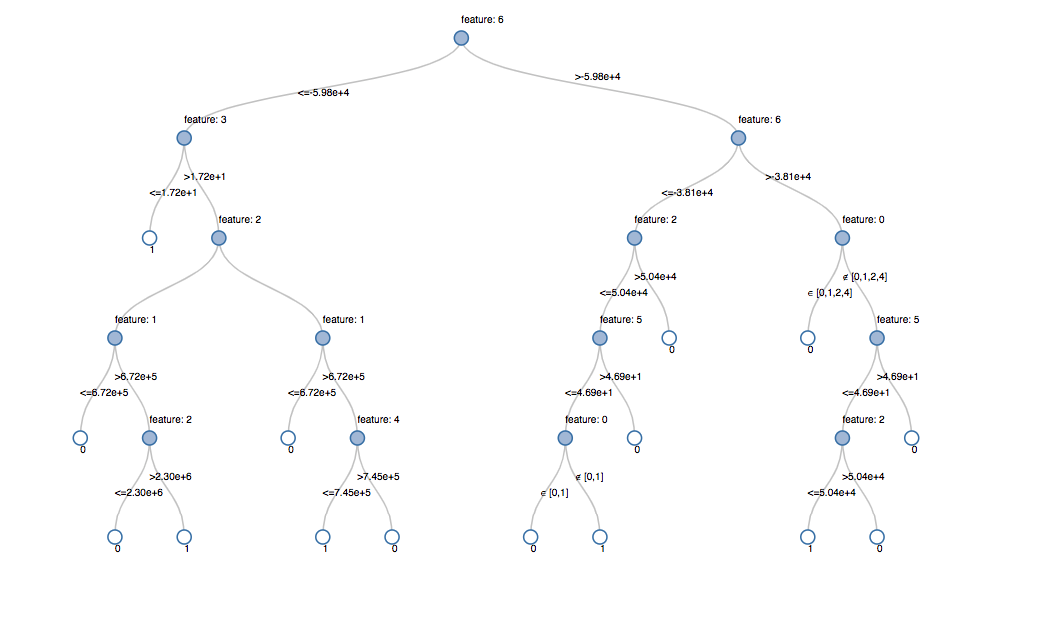 在Databricks Lakehouse中可视化的决策树。
来源://www.neidfyre.com/blog/2019/05/02/detecting-financial-fraud-at-scale-with-decision-trees-and-mlflow-on-databricks.html
在Databricks Lakehouse中可视化的决策树。
来源://www.neidfyre.com/blog/2019/05/02/detecting-financial-fraud-at-scale-with-decision-trees-and-mlflow-on-databricks.html
什么是机器学习中的回归?
数据科学和机器学习中的回归是一种统计方法,能够根据一组输入变量预测结果。结果通常是一个变量,它取决于输入变量的组合。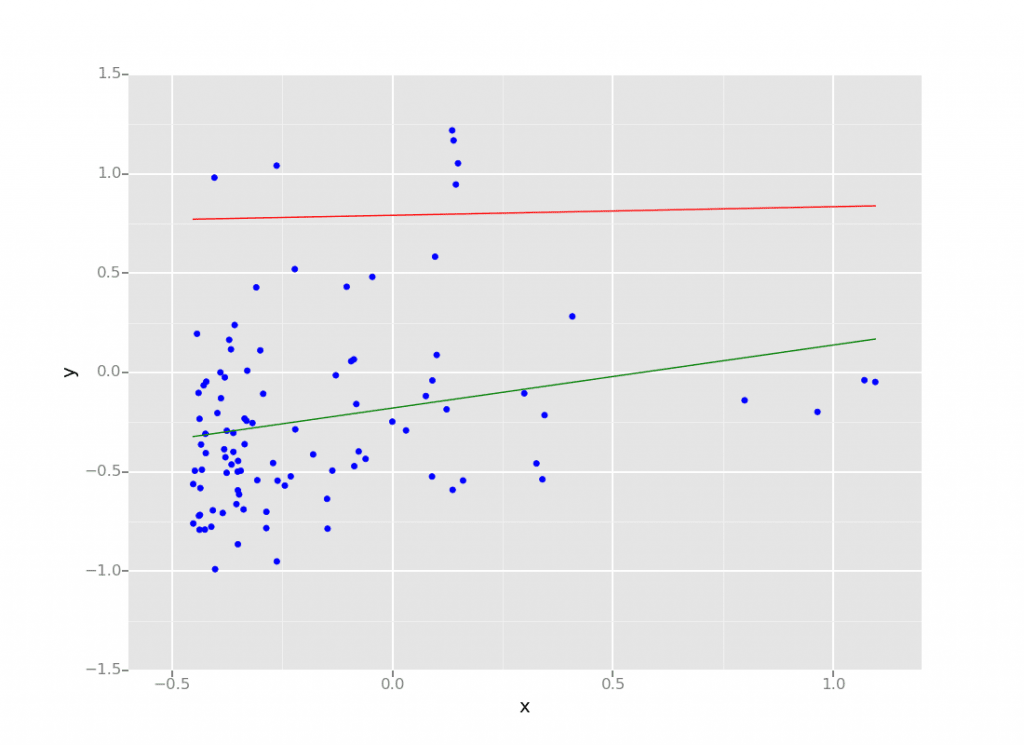 线性回归模型在Databricks Lakehouse上进行。
来源://www.neidfyre.com/blog/2015/06/04/simplify-machine-learning-on-spark-with-databricks.html
线性回归模型在Databricks Lakehouse上进行。
来源://www.neidfyre.com/blog/2015/06/04/simplify-machine-learning-on-spark-with-databricks.html
什么是机器学习中的分类器?
分类器是一种机器学习算法,它将对象分配为类别或组的成员。例如,分类器用于检测电子邮件是否为垃圾邮件,或者交易是否具有欺诈性。机器学习中有多少种模型?
许多!机器学习是一个不断发展的领域,总是有更多的机器学习模型被开发。机器学习的最佳模型是什么?
最适合特定情况的机器学习模型取决于期望的结果。例如,要从历史数据中预测一个城市的车辆购买量,线性回归等监督学习技术可能是最有用的。另一方面,要确定该城市的潜在客户是否会购买汽车,考虑到他们的收入和通勤历史,决策树可能是最有效的。什么是机器学习(ML)中的模型部署?
模型部署是使机器学习模型可用于目标环境(用于测试或生产)的过程。该模型通常通过api与环境中的其他应用程序(如数据库和UI)集成。部署是一个阶段,在这个阶段之后,组织可以实际地从在模型开发中所做的大量投资中获得回报。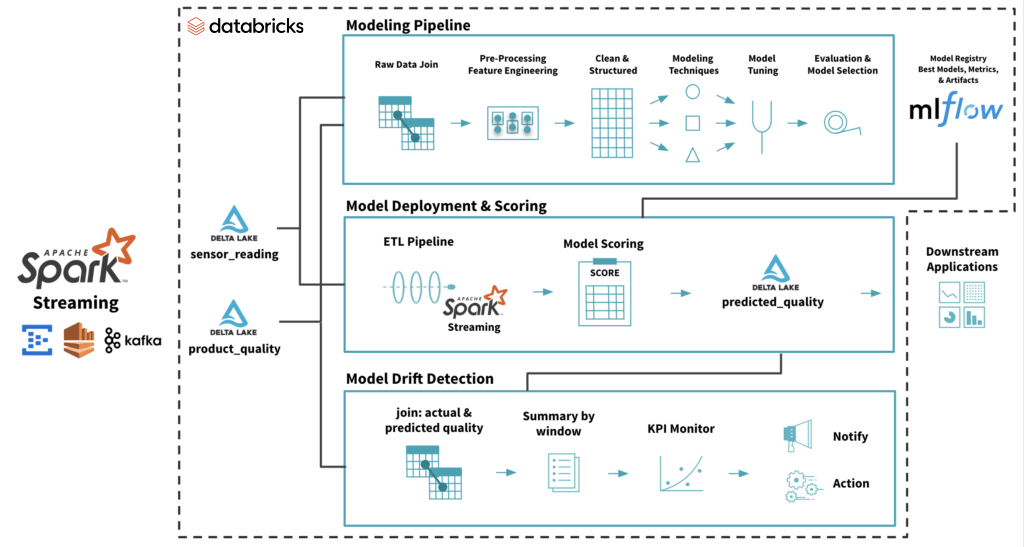 在Databricks Lakehouse上的完整机器学习模型生命周期。
来源://www.neidfyre.com/blog/2019/09/18/productionizing-machine-learning-from-deployment-to-drift-detection.html
在Databricks Lakehouse上的完整机器学习模型生命周期。
来源://www.neidfyre.com/blog/2019/09/18/productionizing-machine-learning-from-deployment-to-drift-detection.html
什么是深度学习模型?
深度学习模型是一类模仿人类处理信息方式的机器学习模型。该模型由几个处理层(因此称为“深度”)组成,从所提供的数据中提取高级特征。每个处理层都将更抽象的数据表示传递给下一层,最后一层提供更类似于人类的见解。与传统的ML模型不同,深度学习模型需要对数据进行标记,可以吸收大量的非结构化数据。它们被用于执行更类似于人类的功能,如面部识别和自然语言处理。 深度学习的简化表示。
来源://www.neidfyre.com/discover/pages/the-democratization-of-artificial-intelligence-and-deep-learning
深度学习的简化表示。
来源://www.neidfyre.com/discover/pages/the-democratization-of-artificial-intelligence-and-deep-learning
什么是时间序列机器学习?
时间序列机器学习模型是其中一个自变量是连续的时间长度(分钟、天、年等),并且与因变量或预测变量有关。时间序列机器学习模型用于预测有时间限制的事件,例如,未来一周的天气,未来一个月的预期客户数量,未来一年的收入指导等等。我可以在哪里了解更多关于BOB低频彩机器学习的知识?
额外的资源
回到术语表
