自动化的偏见
回到术语表什么是自动化偏差?
自动化的偏见过度依赖自动化辅助和决策支持系统。随着自动化决策辅助工具的可用性越来越多地添加到关键决策环境中,如重症监护病房或飞机驾驶舱正变得越来越普遍。人类倾向于选择认知努力最少的道路,同时倾向于“自动化偏见”。同样的概念也可以转化为人工智能和自动化工作的基本方式,主要是基于从大量数据中学习。这种类型的计算假设未来的情况不会有根本的不同。另一个应该考虑的方面是使用有缺陷的训练数据的风险,那么学习将是有缺陷的。什么是机器偏见?
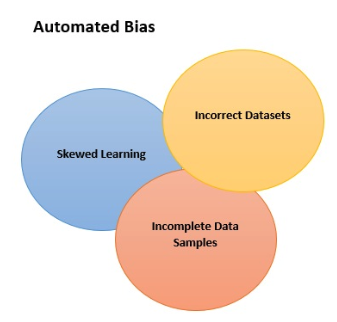
机器的偏见涉及算法显示所使用的算法或其输入数据的偏差的方式。如今,人工智能(AI)正在帮助我们从数据中发现新的见解,并增强人类的决策能力,其中一个例子就是用于登录智能手机的面部识别功能。意外的偏见可能有很多原因(维基百科列出了184个原因),但三个主要的驱动因素是:- 不完整的数据样本
- 不正确的数据集。
- 随着时间的推移,通过互动发生的偏斜学习,也被称为互动偏见
 我们可以通过使用全面而广泛的数据集来防止数据偏差,反映所有可能的边缘用例,数据集越全面,AI预测就越准确。让我们来看看在开发AI时你应该考虑的几个要点。为问题选择正确的学习模式。为了完全避免偏见,可能没有一个单一的模型可以遵循,但有一些参数可以在您的团队构建时通知您。您必须为给定的情况确定最佳模型,并在执行这些想法之前排除故障选择一个有代表性的训练数据集。确保使用的训练数据是多样化的,包括不同的群体。使用真实数据监控性能。在构建算法时,您应该尽可能多地模拟真实的应用程序。
我们可以通过使用全面而广泛的数据集来防止数据偏差,反映所有可能的边缘用例,数据集越全面,AI预测就越准确。让我们来看看在开发AI时你应该考虑的几个要点。为问题选择正确的学习模式。为了完全避免偏见,可能没有一个单一的模型可以遵循,但有一些参数可以在您的团队构建时通知您。您必须为给定的情况确定最佳模型,并在执行这些想法之前排除故障选择一个有代表性的训练数据集。确保使用的训练数据是多样化的,包括不同的群体。使用真实数据监控性能。在构建算法时,您应该尽可能多地模拟真实的应用程序。额外的资源
回到术语表
