



使用Databricks实验室CI/CD模板在Databricks上自动化持续集成和持续交付< / >
为什么我们还需要另一个部署框架?通过可重用模板简化Databricks上的CI/CD使用Databricks部署开发生命周期如何…
2020年6月5日 在工程的博客< / >
Databricks Labs持续集成和持续部署(CI/CD)模板是一种开源工具,它使软件开发团队可以轻松地将现有的CI工具与Databricks Jobs结合使用。bob下载地址此外,它还包含了在Azure和AWS上运行的Databricks最佳实践的管道模板,因此开发人员可以专注于编写重要的代码,而不必从头开始设置完整的测试、集成和部署系统。
CI/CD模板分为3步:
PIP安装cookiecuttercookiecutter https://github.com/databrickslabs/cicd-templates.git
PIP install databricks_cli && databricks configure——token。/ run_pipeline.py管道在项目主目录中你的Databricks实验室CI/CD管道现在将自动运行对Databricks的测试,每当你提交一个新的到repo。当你准备好部署你的代码时,做一个github发布,模板将自动打包并将你的管道部署到databricks作为一个工作。
就是这样!您现在有了一个可伸缩的工作管道,您的开发团队可以使用它进行开发。此外,您可以随时修改模板,使其更特定于您的团队或用例,以确保可以轻松地设置未来的项目。
在这篇文章的剩余部分,我们将深入探讨为什么我们决定创建Databricks Labs CI/CD模板,这个项目的未来计划是什么,以及如何做出贡献。
随着Databricks上的项目越来越大,Databricks用户可能会发现自己难以跟上包含ETL、数据科学实验、仪表板等内容的大量笔记本。虽然有各种短期解决方案,例如使用%run命令从当前笔记本中调用其他笔记本,但遵循传统的软件工程最佳实践将可重用代码与调用该代码的管道分离是有用的。此外,围绕管道构建测试以验证管道也在工作,这是迈向生产级开发流程的另一个重要步骤。
最后,能够在新的代码更改时自动运行作业,而不必手动触发作业或在集群上手动安装库,这对于实现整个管道的可伸缩性和稳定性非常重要。总之,为了扩展和稳定我们的生产管道,我们希望从在笔记本上手动运行代码转向使用传统的软件工程工具(如ide和持续集成工具)自动打包、测试和部署我们的代码。
事实上,越来越多的数据团队正在使用Databricks作为工作负载的运行时,他们更倾向于使用传统的软件工程实践来开发他们的管道:使用ide、GIT和传统的CI/CD管道。这些团队通常希望用单元测试覆盖他们的数据处理逻辑,并在版本控制系统的每次更改后执行集成测试。
发布过程也使用版本控制系统进行管理:在将PR合并到发布分支之后,可以执行集成测试,并且在得到积极结果的情况下,也可以更新部署管道。将新版本的管道引入生产工作区也是一个复杂的过程,因为它们可能有不同的依赖关系,比如配置工件、python和/或maven库和其他依赖关系。在大多数情况下,不同的管道可以依赖于相同工件的不同版本。
许多组织已经为不同的项目投入了大量资源来构建他们自己的CI/CD管道。所有这些管道都有很多共同点:基本上它们构建、部署和测试一些工件。在过去,开发人员也花费大量时间开发不同的脚本,用于构建、测试和部署应用程序,直到CI工具淘汰了大部分这些任务:由CI工具引入的约定使得为开发人员提供框架成为可能,这些框架可以以一种抽象的方式实现这些任务,这样它们就可以应用到任何遵循这些约定的项目中。例如,Maven在Java开发中引入了这样的约定,这使得自动化大部分构建过程成为可能,这些构建过程是在大型ant脚本中实现的。
Databricks Labs CI/CD Templates使得使用现有的CI/CD工具(如Jenkins)与Databricks;模板包含根据Databricks最佳实践创建的预先制作的代码管道。此外,模板允许团队将他们的CI/CD管道打包成可重用的代码,以简化未来项目的创建和部署。Databricks Labs CI/CD Templates为数据工程和数据科学项目引入了类似的约定,这些项目为使用Databricks的数据从业者提供了抽象工具,用于为他们的数据应用程序实现CI/CD管道。
让我们更深入地研究一下我们已经介绍过的约定。大部分数据处理逻辑,包括数据转换、特征生成逻辑、模型训练等都应该在python包中开发。这种逻辑可以在许多可以作为作业调度的生产管道中使用。前面提到的逻辑也可以使用测试单个转换函数和集成测试的局部单元测试进行测试。集成测试在Databricks工作空间上运行,可以对整个数据管道进行测试。
数据工程师和数据科学家可以依靠Databricks Labs CI/CD模板在Databricks本地测试和部署他们在ide中开发的代码。Databricks Labs CI/CD Templates为用户提供了可重用的数据项目模板,可用于快速启动新数据用例的开发。本项目结构如下:
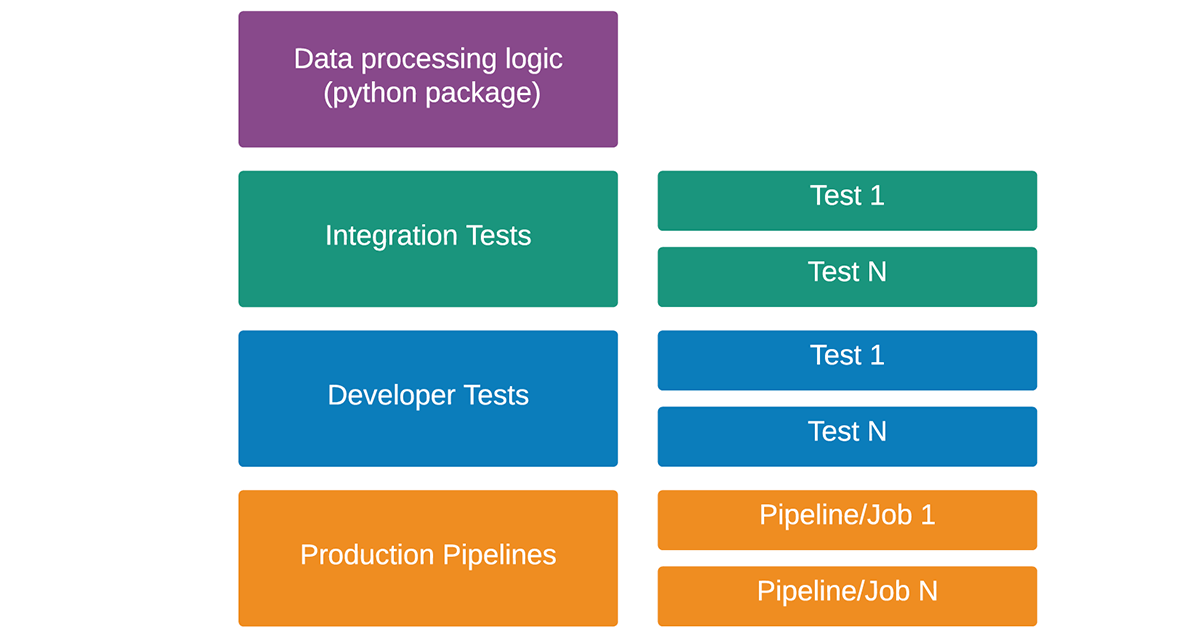
数据摄取、验证和转换逻辑,以及特征工程和机器学习模型,都可以在python包中开发。生产管道可以利用此逻辑,并使用开发人员和集成测试进行测试。Databricks实验室CI/CD模板可以部署生产管道Databricks作业,自动包括所有依赖项.这些管道必须放置在管道目录中,并且可以有自己的依赖集,包括不同的库和配置工件。开发人员可以利用Apache Spark或Databricks Connect的本地模式来测试代码,同时在安装在笔记本电脑上的IDE中开发。如果他们想在Databricks上运行这些管道,他们可以使用Databricks Labs CI/CD Templates CLI。开发人员还可以利用CLI在Databricks上启动项目当前状态的集成测试。
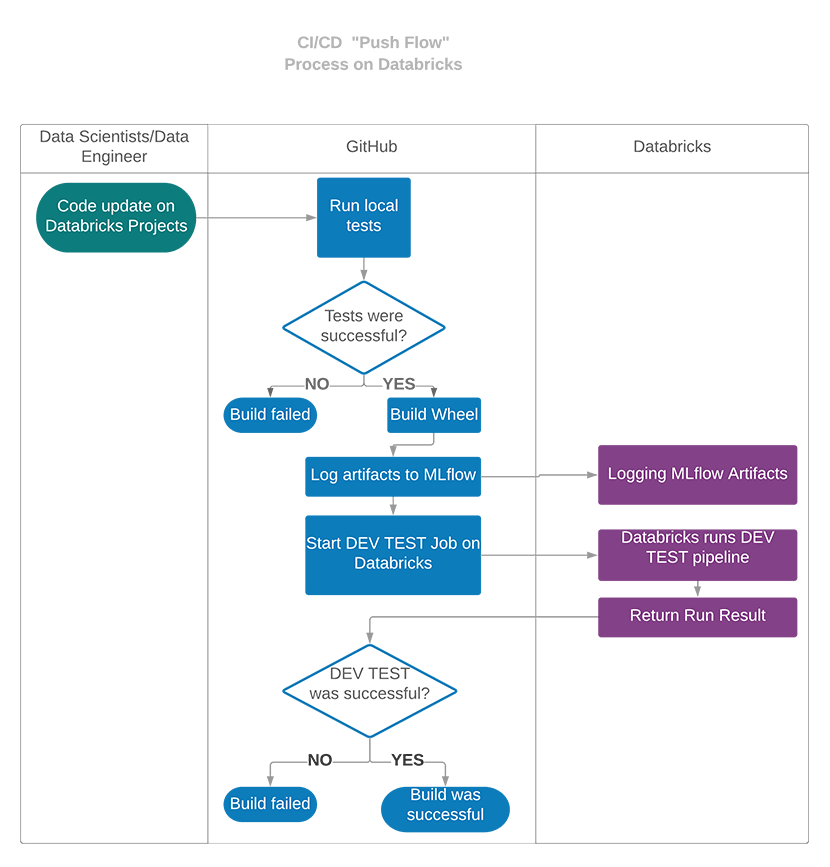
在此之后,用户可以将更改推送到GitHub,在那里他们将使用GitHub Actions配置在Databricks上自动测试。每次推送后,GitHub Actions都会启动一个VM,该VM会检出项目的代码,并在该VM中运行本地pytest测试。如果这些测试成功,它将构建python轮,并将其与Databricks的所有其他依赖项一起部署到Databricks,并在Databricks上运行开发人员测试。
在开发周期结束时,整个项目可以通过创建一个GitHub版本部署到生产环境中,该版本将在Databricks中启动集成测试,并将生产管道部署为Databricks job。在这种情况下,CI/CD管道将与前面的管道类似,但是集成测试将在Databricks上运行,而不是开发人员测试,如果它们成功,则将更新Databricks上的生产作业规范。
PIP安装cookiecuttercookiecutter https://github.com/databrickslabs/cicd-templates.git在此之后,将为您创建新项目。它将具有以下结构:
.├──cicd_demo│├──__init__.py│├──数据││├─__init__.py││├──make_dataset.py│├──││效果器整理www.catsound.cat││├─__init__.py││├──build_features.py│├──模型││├─__init__.py││├──predict_model.py││├──train_model.py│├──可视化│├──__init__.py│├──│├。py├──create_cluster.py├──部署│└──databrickslabs_mlflowdepl -0.2.0-py3-none -任何.whl├──deployment.yaml├──dev-tests│├──pipeline1││├──job_spec_aws.json││├──job_spec_azure.json││├──pipeline_runner.py│├──pipeline2│├──job_spec_aws.json│├──job_spec_azure.json│├──pipeline_runner.py├──文档│├──Makefile│├──rammstein .rst│├──conf.py│├──rammstein -start .rst│├──index.rst│├──rammstein .bat├──集成测试│├──pipeline1││├──job_spec_aws.json││├──job_spec_azure.json││├──pipeline_runner.py│├──pipeline2│├──job_spec_aws.json│├──job_spec_azure.json│├──pipeline_runner.py├──笔记本├──管道│├──pipeline1││├──job_spec_aws.json││├──job_spec_azure.json││├──pipeline_runner.py│├──pipeline2│├──job_spec_aws.json│├──job_spec_azure.json│├──pipeline_runner.py├──让├──run_pipeline.py├──runtime_requirements.txt├──setup . py└──测试└──test_smth.py< / >我们创建的项目的名称是' cicd_demo ',因此python包的名称也是' cicd_demo ',因此我们的转换逻辑将在' cicd_demo '目录中开发。它可以从将被放置在' pipelines '目录中的管道中使用。在“管道”目录中,我们可以开发许多管道,每个管道都在自己的目录中。
每个管道必须有一个入口点python脚本,必须命名为' pipeline_runner.py '。在这个项目中,我们可以看到创建了两个示例管道。每个管道都为每个受支持的云提供python脚本和作业规范json文件。这些文件可用于定义集群规范(例如,节点数量、实例类型等)、作业调度设置等。
“Dev-tests”和“integration-tests”目录用于定义在Databricks中测试管道的集成测试。他们还应该利用python包中开发的逻辑,并评估转换的结果。
Databricks部署与GitHub Actions紧密集成。我们需要创建一个新的GitHub存储库,在那里我们可以推送我们的代码,在那里我们可以利用GitHub动作来自动测试和部署我们的管道。为了将GitHub存储库与Databricks工作空间集成,必须将工作空间URL和个人身份验证令牌(PAT)配置为GitHub机密。工作区URL必须配置为DATABRICKS_HOST secret, token必须配置为DATABRICKS_TOKEN。
现在我们可以在项目目录中初始化一个新的git存储库。之后,我们可以将所有文件添加到git中,并将它们推送到远程GitHub存储库中。在我们配置了令牌并进行了第一次推送后,GitHub Actions将自动在目标Databricks Workspace上运行dev-test,如果测试成功,我们的第一次提交将被标记为绿色。
通过运行run_pipeline.py脚本,可以在本地环境中启动生产管道或Databricks上的单独测试:
./run_pipeline.py管道——pipeline-name test_pipeline新创建的项目预先配置了两个标准CI/CD管道:其中一个为每次推送执行,并在Databricks工作空间上运行dev-tests。
另一个是为每个创建的GitHub版本运行,并在Databricks工作空间上运行集成测试。在集成测试得到积极结果的情况下,生产管道将作为作业部署到Databricks工作区。
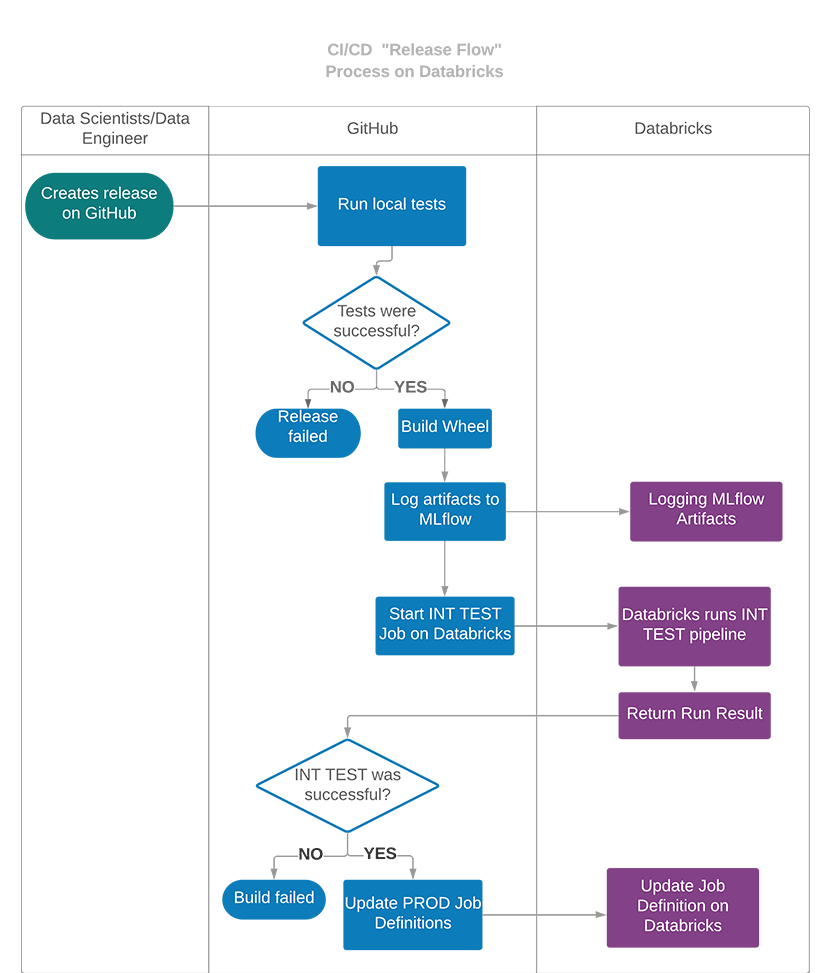
为了将管道部署到生产工作区,可以创建GitHub发行版。它将自动启动集成测试,如果测试结果为正,则将生产管道作为作业部署到Databricks工作区。在第一次运行期间,作业将在Databricks工作区中创建。在后续版本中,将更新现有作业的定义。
Databricks部署支持两个级别的依赖关系管理:
配置文件可以放在管道目录中。它们将与python脚本一起被记录到MLflow。在Databricks中执行时,作业脚本将接收到管道文件夹的路径作为第一个参数。此参数可用于打开管道目录中存在的任何文件。
让我们通过下面的例子来讨论如何使用Databricks部署来管理依赖关系:
.├──依赖性│├──罐子││├──direct_dep.jar│├──车轮│├──ramotherwheel -0.1.0-py3-none -任何.whl├──job_spec_aws.json├──job_spec_azure.json├──pipeline_runner.py└──train_config.yaml该管道在管道级别上有两个依赖项:一个jar文件和一个轮子。Train_config。Yaml文件包含管道可以使用以下代码读取的配置参数:
defread_config(名字,根):试一试:文件名= root.replace(“dbfs:”,' / dbfs ') +' / '+名字与开放(文件名)作为conf_file:Conf = yaml。负载(conf_file装载机= yaml.FullLoader)返回相依除了FileNotFoundError作为艾凡:提高FileNotFoundError (f”{e}.请附上配置文件!”)Conf = read_config(“train_config.yaml”, sys.argv [1])Databricks部署的进一步发展有不同的方向。我们正在考虑扩展一组CI/CD工具,我们为其提供模板。到目前为止,它只是GitHub Actions,但我们可以添加一个与CircleCI或Azure DevOps集成的模板。
另一个方向是支持用Scala开发的管道的开发。
Databricks Labs CI/CD Templates是一个开源工具bob下载地址,我们非常欢迎对它的贡献。欢迎您提交PR!