


使用MLflow、Apache Spark MLlib和Hyperopt进行超参数调优
超参数调优是一种常见的技术,用于基于超参数或模型训练中没有学习到的配置来优化机器学习模型。
超参数调优是一种常见的技术,用于基于超参数或模型训练中未学习到的配置来优化机器学习模型。调整这些配置可以极大地提高模型性能。然而,超参数调优在计算上可能是昂贵的,缓慢的,甚至对专家来说也是不直观的。
Databricks运行时5.4和5.4 ML (Azure|AWS)引入了有助于扩展和简化超参数调优的新功能。这些特性支持Python中的ML调优,重点是通过Apache Spark实现可伸缩性,并通过MLflow实现自动跟踪。
超参数调优会创建复杂的工作流程,包括测试许多超参数设置、生成许多模型以及在ML管道上迭代。为了简化调优工作流的跟踪和再现性,我们使用MLflow,一个开源bob下载地址平台,帮助bob体育客户端下载管理完整的机器学习生命周期。BOB低频彩中了解有关MLflow的更多信息MLflow文档最近的Spark+AI峰会2019 MLflow会谈.
我们的集成鼓励使用一些最佳实践来组织运行和跟踪超参数调优。在高层次上,我们按照以下方式组织运行,匹配调优本身使用的结构:
| 调优 | MLflow运行 | MLflow日志 |
| 超参数调谐算法 | 父母运行 | 元数据,例如numFolds forCrossValidator |
| 拟合和评估模型,超参数设置#1 | 子运行1 | 超参数#1,评估指标#1 |
| 用超参数设置#2拟合和评估模型 | 子运行2 | 超参数2,评估指标2 |
| ... | ... | ... |
如欲了BOB低频彩解更多,请观看有关“MLflow超参数调优的最佳实践在2019年Spark+AI峰会上。
托管MLflow现在通常可以在Databricks上找到,当MLflow库安装在集群上时,我们接下来讨论的两个集成在默认情况下利用托管MLflow。
Apache Spark MLlib用户经常使用MLlib的内置工具调优超参数CrossValidator而且TrainValidationSplit.它们使用网格搜索来尝试用户指定的超参数值集;看到关于调优的Spark文档更多信息。
Databricks Runtime 5.3和5.3 ML及以上版本支持MLlib Python调优的自动MLflow跟踪。
有了这个功能,PySparkCrossValidator而且TrainValidationSplit将自动记录到MLflow,在层次结构中组织运行,并记录超参数和评估指标。例如,调用CrossValidator.fit ()将记录一个父运行。在这种情况下,CrossValidator将记录每个超参数设置的一个子运行,并且每个子运行将包括超参数设置和评估度量。在MLflow UI中比较这些运行有助于可视化调优每个超参数的效果。
https://www.youtube.com/watch?v=DFn3hS-s7OA
在Databricks Runtime 5.3和5.3 ML中,自动跟踪默认不启用。若要开启自动跟踪,请设置Spark配置spark.databricks.mlflow.trackMLlib.enabled“真正的”。对于5.4版本,默认情况下启用了自动跟踪。
Hyperopt是一个流行的开源超参数调优库,具有强大的社区支持(截至2019年5月,PyPI下载超过600,000次,Github上的星星超过3300颗)。数据科学家使用Hyperopt是因为它的简单和有效。Hyperopt提供了两种调优算法:随机搜索和Parzen Estimators的贝叶斯方法树,与网格搜索等暴力方法相比,它提供了更高的计算效率。然而,分发Hyperopt以前不能开箱即用,需要手动设置。
在Databricks Runtime 5.4 ML中,我们介绍了一个由Apache Spark驱动的Hyperopt实现。使用新的试用类SparkTrials,您可以轻松地分发一个Hyperopt运行,而不需要对当前的Hyperopt api做任何更改。你只需要通过SparkTrials类时,应用hyperopt.fmin ()函数(请参阅下面的示例代码)。此外,所有调优实验以及它们的超参数和评估指标都会自动记录到Databricks中的MLflow中。有了这个特性,我们的目标是提高超参数调优工作流的效率、可伸缩性和简单性。
#新的SparkTrials类,用于分发调优spark_trials = SparkTrials(并行度=24) < / b >
fmin (fn =火车,#训练和评估模型的方法空间= search_space,定义超参数的空间算法= tpe.suggest,#搜索算法:Parzen估计树max_evals =8,#尝试设置超参数的次数show_progressbar =假,
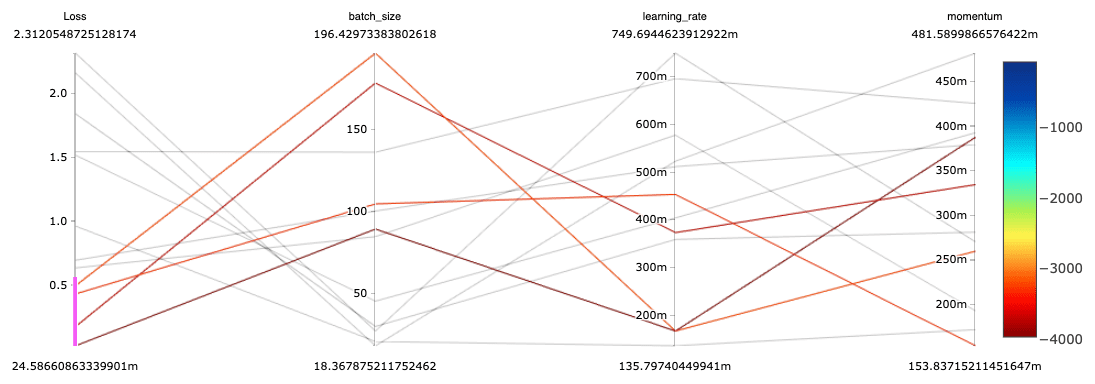
试验= < b > spark_trials < / b >)结果可以使用平行坐标图等工具可视化。在下面的图表中,我们可以看到,具有最佳(最低)损失的深度学习模型是使用中到大批量、小到中学习率和各种动量设置进行训练的。注意,这个图是通过手工制作的情节,但是MLflow将在不久的将来为并行坐标图提供原生支持。
在Databricks,我们拥抱开源社区和api。bob下载地址我们正在与Hyperopt社区合作,将这个spark驱动的实现贡献给开源Hyperopt。bob下载地址请继续关注。
要了解BOB低频彩关于超参数调优的更多信息:
要了解BOB低频彩关于MLflow的更多信息,请查看这些资源:
要开始使用这些特定功能,请查看以下文档页及其嵌入式示例笔记本。尝试使用新的Databricks Runtime 5.4 ML发行版。