
使用动态时间翘曲和MLflow检测销售趋势


2019年4月30日 在工程的博客
这篇博客是我们两部分系列文章的第2部分< >强使用动态时间翘曲和MLflow检测销售趋势.
“动态时间扭曲”这个词,乍一读,可能会让人联想到马蒂·麦克弗莱(Marty McFly)驾驶着他的德罗宁(DeLorean)以88英里/小时的速度行驶在纽约回到未来系列。唉,动态时间扭曲并不涉及时间旅行;相反,它是一种用于在比较数据点之间的时间指数不能完美同步时动态比较时间序列数据的技术。
正如我们将在下面探讨的那样,动态时间扭曲最突出的用途之一是在语音识别中-确定一个短语是否与另一个短语匹配,即使这个短语说得比它的比较快或慢。你可以想象,这在识别用于激活谷歌Home或亚马逊Alexa设备的“唤醒词”时很方便——即使你的说话速度很慢,因为你还没有喝每天的一杯咖啡。
动态时间翘曲是一种有用的、功能强大的技术,可以应用于许多不同的领域。一旦理解了动态时间扭曲的概念,就很容易看到它在日常生活中的应用实例,以及它令人兴奋的未来应用。考虑以下用途:
- 金融市场-比较相似时间范围内的股票交易数据,即使它们并不完全匹配。例如,比较2月(28天)和3月(31天)的月度交易数据。
- 可穿戴健身追踪器-更准确地计算步行者的速度和步数,即使他们的速度随时间变化。
- 路径计算-如果我们了解司机的驾驶习惯(例如,他们在直道上开得很快,但左转的时间比平均时间要长),就可以计算出更准确的司机的预计到达时间。
数据科学家、数据分析师和任何与时间序列数据打交道的人都应该熟悉这种技术,因为完全对齐的时间序列比较数据与完全“整齐”的数据一样罕见。
在本系列博客中,我们将探讨:
- 动态时间翘曲的基本原理
- 对采样音频数据进行动态时间扭曲
- 使用MLflow对样例销售数据运行动态时间扭曲
有关动态时间扭曲的更多背景知识,请参阅前一篇文章理解动态时间扭曲.
背景
想象一下,你拥有一家制造3D打印产品的公司。去年,你知道无人机螺旋桨的需求非常稳定,所以你生产并销售这些螺旋桨,前年你销售手机壳。新的一年很快就要到来了,你和你的生产团队坐下来讨论你的公司明年应该生产什么。为你的仓库购买3D打印机会让你负债累累,所以你必须确保你的打印机在任何时候都以或接近100%的容量运行,以支付他们的费用。
既然你是一个明智的CEO,你知道你的生产能力在接下来的一年里会有起伏——会有几个星期你的生产能力高于其他公司。例如,您的产能可能在夏季较高(当您雇用季节性工人时),而在每月的第三周较低(因为3D打印机灯丝供应链的问题)。请看下面的图表,看看贵公司的生产能力估算:
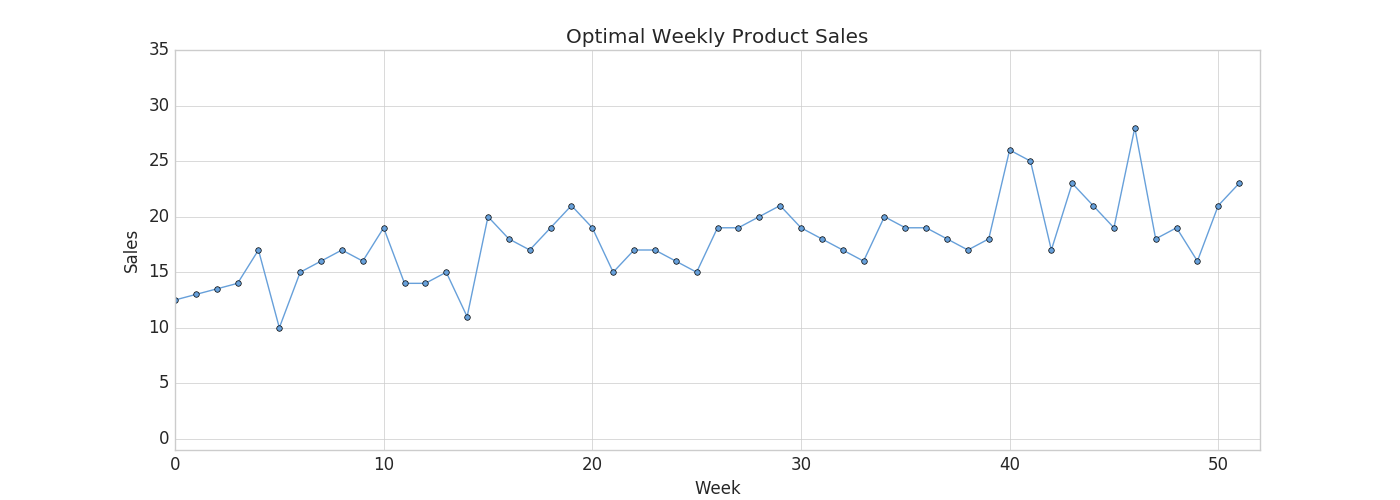
你的任务是选择一种每周需求能尽可能满足你生产能力的产品。你正在查看一份产品目录,其中包括去年每种产品的销售数字,你认为今年的销售情况将与此类似。
如果你选择的产品每周的需求超过了你的生产能力,那么你将不得不取消客户的订单,这对业务是不利的。另一方面,如果你选择的产品没有足够的周需求,你将无法让你的打印机满负荷运行,可能无法偿还债务。
动态时间扭曲在这里发挥作用,因为有时您所选择的产品的供求会略有不同步。会有几周你没有足够的产能来满足你所有的需求,但只要你非常接近,你可以在一两周内生产更多的产品来弥补,你的客户不会介意的。如果我们限制自己使用欧几里得匹配比较销售数据和生产能力,我们可能会选择一个没有考虑到这一点的产品,并把钱留在桌子上。相反,我们将使用动态时间扭曲来选择适合贵公司今年的产品。
加载产品销售数据集
我们将使用每周销售交易数据集在UCI数据集存储库执行基于销售的时间序列分析。(来源:James Tan, jamestansc '@' suss.edu.sg,新加坡社会科学大学)
进口熊猫作为pd#使用Pandas读取数据Sales_pdf = pd。read_csv (sales_dbfspath头=“推断”)#回顾数据显示器(spark.createDataFrame (sales_pdf))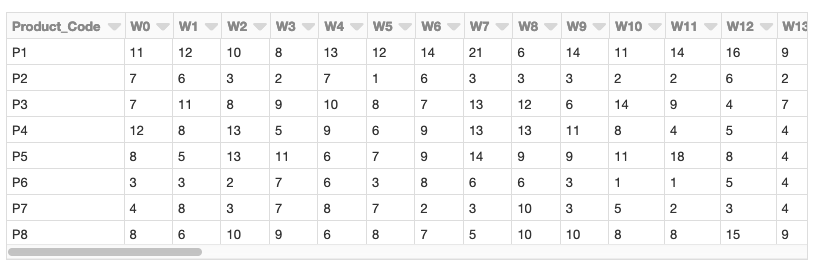
每个产品用一行表示,一年中的每个星期用一列表示。数值表示每种产品每周销售的单位数。数据集中有811种产品。
通过产品代码计算到最佳时间序列的距离
#通过动态时间扭曲计算产品代码和最佳时间序列之间的距离进口numpy作为np进口_ucrdtwdefget_keyed_values(年代):返回(s (0,年代1:])defcompute_distance(行):返回(行0), _ucrdtw.ucrdtw (列表(行1] [0:52]),列表(optimal_pattern),0.05,真正的) [1])ts_values = pd.DataFrame(np.apply_along_axis(get_keyed_values,1, sales_pdf.values))距离= pd.DataFrame(np.apply_along_axis(compute_distance,1, ts_values.values))距离。列= [“pcode”,“dtw_dist”]使用计算的动态时间扭曲“距离”列,我们可以在直方图中查看DTW距离的分布。
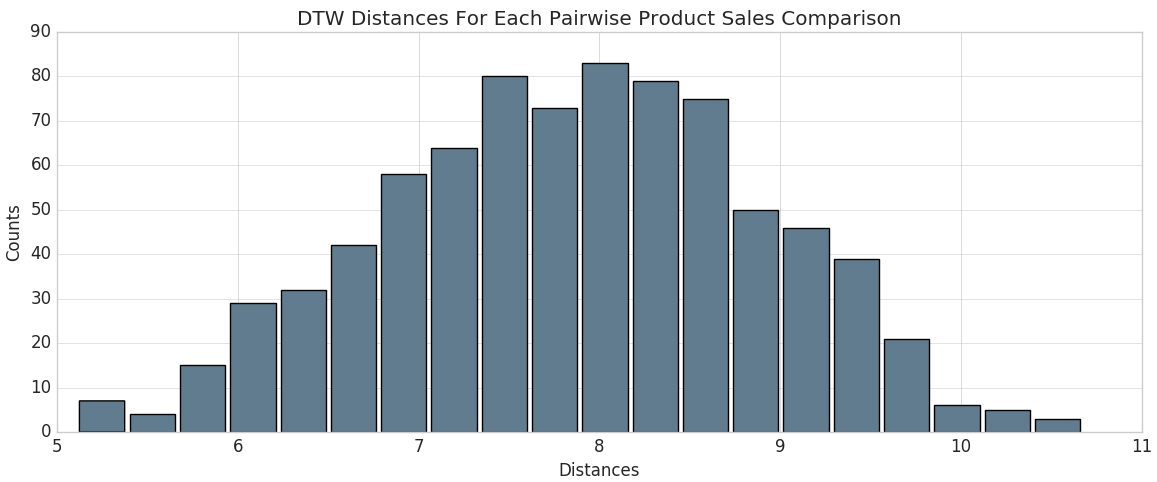
由此,我们可以识别出最接近最佳销售趋势的产品代码(即具有最小计算DTW距离的产品代码)。因为我们使用的是Databricks,所以我们可以使用SQL查询轻松地进行选择。让我们显示那些最接近的。
%sql——最接近最佳销售趋势的前10个产品代码选择pcode,投(dtw_dist作为浮动)作为dtw_dist从距离订单通过投(dtw_dist作为浮动)限制10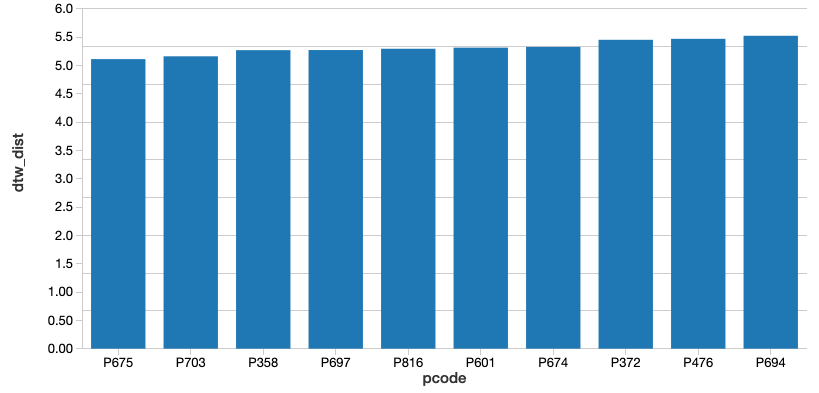
运行此查询之后,将对产品代码进行相应的查询最远的从最优销售趋势中,我们能够识别出离趋势最近和最远的两种产品。让我们画出这两种产品,看看它们有什么不同。
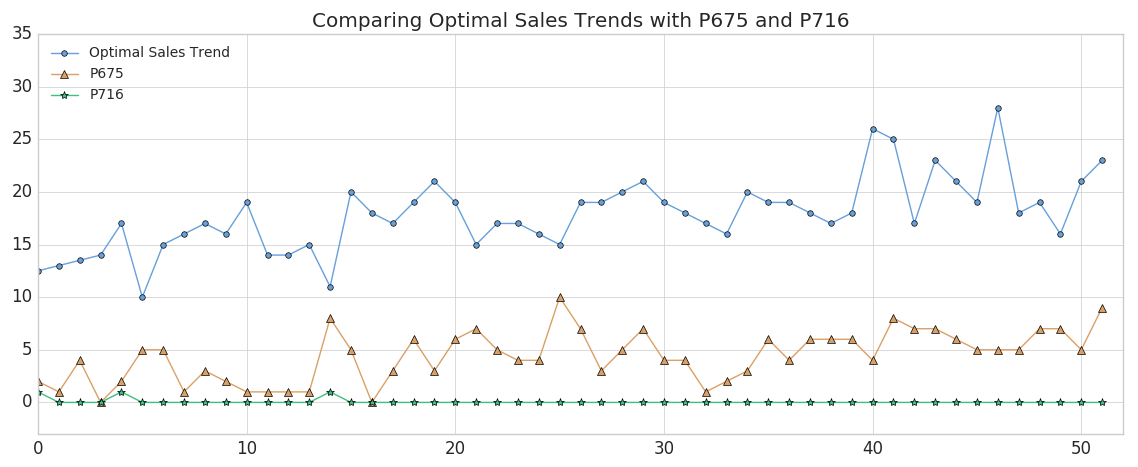
如您所见,产品#675(显示在橙色三角形)代表了与最佳销售趋势的最佳匹配,尽管绝对周销量低于我们的期望(我们将在后面进行补救)。这个结果是有意义的,因为我们期望具有最近DTW距离的产品具有某种程度上反映我们所比较的度量的峰值和低谷。(当然,由于动态时间扭曲,产品的确切时间指数每周都会发生变化)。相反,产品#716(显示在绿色Stars)是匹配最差的产物,几乎没有变化。
寻找最佳产品:较小的DTW距离和相似的绝对销量
现在我们已经开发了一个最接近我们工厂预计产量的产品列表(我们的“最优销售趋势”),我们可以将它们筛选到DTW距离较小但绝对销售数字相似的产品。一个很好的候选产品是产品#202,它的DTW距离为6.86,而总体中位数距离为7.89,非常接近我们的最佳趋势。
回顾P202周销售情况Y_p202 = sales_pdf[sales_pdf]“Product_Code”) = =“P202”) . values (0] [1:53]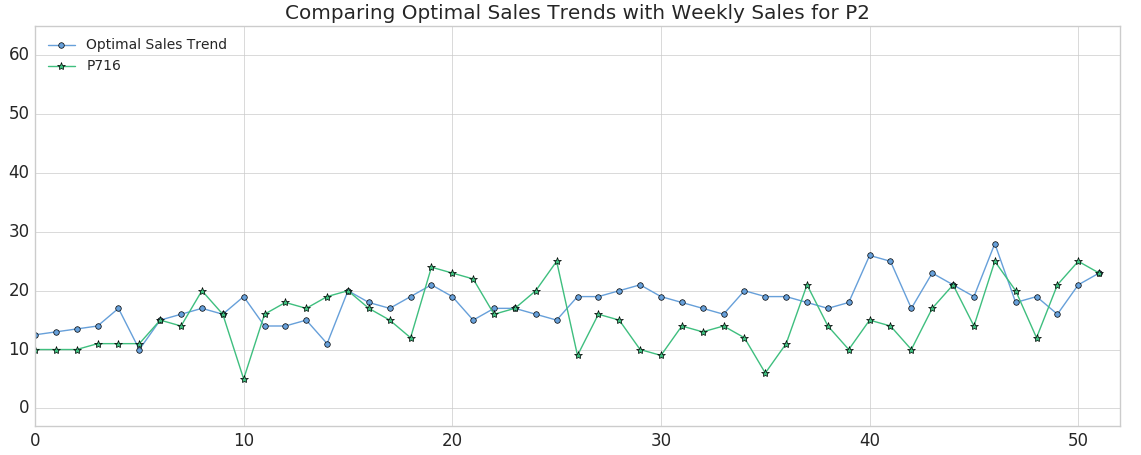
使用MLflow跟踪最好和最差的产品,以及工件
MLflow是一个用于管bob下载地址理机器学习bob体育客户端下载生命周期的开源平台,包括实验、重现性和部署。Databricks笔记本提供了一个完全集成的MLflow环境,允许您创建实验,记录参数和指标,并保存结果。有关如何开始使用MLflow的更多信息,请参阅优秀的文档文档.
MLflow的设计围绕着以系统的、可重复的方式记录我们所做的每个实验的所有输入和输出的能力。在每次通过数据时,称为“运行”,我们能够记录我们的实验:
- 参数-模型的输入。
- 指标-我们模型的输出,或者我们模型成功的度量。
- 工件-由我们的模型创建的任何文件-例如,PNG图或CSV数据输出。
- 模型-模型本身,我们可以稍后重新加载并使用它来进行预测。
在我们的例子中,我们可以使用它对数据多次运行动态时间扭曲算法,同时更改“拉伸因子”,即可以应用于时间序列数据的最大扭曲量。启动MLflow实验,并允许轻松使用日志记录mlflow.log_param (),mlflow.log_metric (),mlflow.log_artifact (),mlflow.log_model (),我们使用:
与mlflow.start_run ()作为运行:...如下缩位代码所示。
进口mlflowdefrun_DTW(ts_stretch_factor):#计算每个产品的DTW距离和z得分< >强与mlflow.start_run ()作为运行:< / >强#使用自定义风味的日志模型Dtw_model = {“stretch_factor”:浮动(ts_stretch_factor),“模式”: optimal_pattern}< >强mlflow_custom_flavor.log_model (dtw_model artifact_path =“模型”) < / >#将拉伸因子参数记录到MLflow< >强mlflow.log_param (“stretch_factor”ts_stretch_factor) < / >强#记录这次跑的中位DTW距离< >强mlflow.log_metric (“中间的距离”distance_median) < / >强#日志工件- CSV文件和PNG情节- MLflow< >强mlflow.log_artifact (“zscore_outliers_”+str(ts_stretch_factor) +. csv”)mlflow.log_artifact (“DTW_dist_histogram.png”)返回run.info < / >强Stretch_factors_to_test = [0.0,0.01,0.025,0.05,0.1,0.25,0.5]为n在stretch_factors_to_test:run_DTW (n)在每次遍历数据时,我们都创建了使用的“拉伸因子”参数的日志,以及基于DTW距离度量的z分值将产品分类为异常值的日志。我们甚至能够保存DTW距离直方图的工件(文件)。这些实验运行被保存在本地的Databricks上,如果您决定在以后的日期查看实验结果,可以在将来访问它们。
现在MLflow已经保存了每个实验的日志,我们可以回顾并检查结果。从Databricks笔记本中,选择![]() 图标的右上角,以查看和比较我们每次运行的结果。
图标的右上角,以查看和比较我们每次运行的结果。
https://www.youtube.com/watch?v=62PAPZo-2ZU
毫不奇怪,当我们增加“拉伸因子”时,我们的距离指标就会减少。直观地说,这是有意义的:当我们赋予算法更大的灵活性来向前或向后扭曲时间索引时,它将找到更适合数据的值。本质上,我们用一些偏差换取了方差。
MLflow中的日志记录模型
MLflow不仅能够记录实验参数、指标和工件(如图表或CSV文件),还能够记录机器学习模型。MLflow Model只是一个文件夹,其结构符合一致的API,确保与其他MLflow工具和特性兼容。这种互操作性非常强大,允许将任何Python模型快速部署到许多不同类型的生产环境中。
MLflow预装了许多最流行的机器学习库的通用模型“口味”,包括scikit-learn、Spark MLlib、PyTorch、TensorFlow等。这些模型风格使得在初始构造模型后记录和重新加载模型变得很简单,如下所示博客.例如,当与scikit-learn一起使用MLflow时,记录模型就像在实验中运行以下代码一样简单:
mlflow.sklearn.log_model(模型= sk_model artifact_path =“sk_model_path”)MLflow还提供了一种“Python函数”风格,它允许您将来自第三方库(如XGBoost或spaCy)的任何模型,甚至是简单的Python函数本身,保存为MLflow模型。使用Python函数风格创建的模型存在于同一个生态系统中,并且能够通过Inference API与其他MLflow工具交互。尽管不可能为每个用例进行计划,但Python函数模型风格被设计为尽可能通用和灵活的。它允许自定义处理和逻辑计算,这在ETL应用程序中可以派上用场。即使更多的“官方”模型风格上线,通用的Python函数风格仍将作为重要的“全能”,在任何类型的Python代码和MLflow健壮的跟踪工具包之间提供桥梁。
使用Python函数风格记录模型是一个简单的过程。任何模型或函数都可以保存为model,但有一个要求:它必须包含熊猫Dataframe作为输入,并返回DataFrame或NumPy数组。一旦满足了这个要求,将函数保存为MLflow Model需要定义一个继承自PythonModel的Python类,并覆盖.predict ()方法,如所述在这里.
从我们的运行中加载一个日志模型
现在我们已经用几个不同的拉伸因子遍历了我们的数据,接下来自然是检查我们的结果,并根据我们记录的指标寻找一个表现特别好的模型。MLflow可以很容易地重新加载日志模型,并使用它对新数据进行预测,使用以下指令:
- 点击你想要加载我们模型的运行的链接。
- 复制“运行ID”。
- 注意存储模型的文件夹的名称。在我们的例子中,它被简单地命名为“model”。
- 输入模型文件夹名称和运行ID,如下所示:
进口custom_flavor作为mlflow_custom_flavorLoaded_model = mlflow_custom_flavor.load_model(artifact_path=“模型”run_id =“e26961b25c4d4402a9a5a7a679fc8052”)为了显示我们的模型是按预期工作的,我们现在可以加载模型并使用它来测量我们在变量中创建的两个新产品的DTW距离new_sales_units:
#使用模型评估在“new_sales_units”中发现的新产品Output = loaded_model.predict(new_sales_units)打印(输出)下一个步骤
如您所见,我们的MLflow模型可以轻松预测新的和未见的值。由于它符合Inference API,我们可以在任何服务平台上部署我们的模型(例如bob体育客户端下载微软Azure ML,或亚马逊Sagemaker),将其部署为本地REST API端点,或创建用户定义函数(UDF)可以很容易地与Spark-SQL一起使用。最后,我们演示了如何使用动态时间扭曲来使用Databricks预测销售趋势bob体育亚洲版统一分析平台。bob体育客户端下载试试利用动态时间翘曲和MLflow预测销售趋势笔记本Databricks运行时机器学习今天。