
Apache火花不包括一个流API为XML文件。然而,您可以把自动装载器的特征OSS的火花批API库,Spark-XML流的XML文件。
在本文中,我们提出一个基于Scala解析XML数据使用一个装载器的解决方案。
安装Spark-XML图书馆
你必须安装Spark-XMLOSS图书馆集群砖上。
检查集群上安装一个库(AWS|Azure)文档以了解更多的细节。
创建XML文件
创建XML文件,并使用DBUtils (AWS|Azure),将其保存到您的集群。
% scala val xml2 = " " <人> <人> <年龄出生= " 1990-02-24 " > 25岁< / > < /人> <人> <年龄出生= " 1985-01-01 " > 30岁< / > < /人> <人> <年龄出生= " 1980-01-01 " > 30岁< / > < /人> < /人> " " dbutils.fs.put (" / < path-to-save-xml-file > / < name-of-file > . xml”, xml2)
定义进口
进口所需的功能。
% scala进口com.databricks.spark.xml.functions.from_xml com.databricks.spark.xml进口。schema_of_xml spark.implicits进口。_进口com.databricks.spark.xml。_进口org.apache.spark.sql.functions。{< input_file_name >}
定义一个UDF将二进制转换为字符串
流DataFrame需要字符串格式的数据。
你应该定义一个用户定义的函数将二进制数据转换成字符串数据。
% scala val toStrUDF = udf((字节:数组(字节))= >新字符串(字节,“utf - 8”))
提取XML模式
你必须提取XML模式才能实现流媒体DataFrame。
这可以推断从文件使用schema_of_xml从Spark-XML方法。
XML字符串作为输入,通过二进制火花数据。
% scala val df_schema = spark.read.format (binaryFile) .load (“/ FileStore /表/测试/ xml /数据/年龄/”).select (toStrUDF(“内容”)美元.alias(“文本”))val payloadSchema = schema_of_xml (df_schema.select(“文本”)。as [String])
实现流读取器
在这一点上,所有必需的依赖项已满足,所以你可以实现流的读者。
使用readStream二进制和自动装卸机清单模式选项启用。
toStrUDF用于二进制数据转换为字符串格式(文本)。
from_xml用于将字符串转换为一个复杂的结构类型,与用户定义的模式。
% scala val df = spark.readStream.format .option (“cloudFiles (“cloudFiles”)。useNotifications”、“假”)/ /使用清单模式,因此使用假.option (“cloudFiles。格式”、“binaryFile”) .load (“/ FileStore /表/测试/ xml /数据/年龄/”).select (toStrUDF(“内容”)美元.alias(“文本”))/ / UDF将二进制转换成字符串.select (from_xml(“文本”美元,payloadSchema) .alias(“解析”))/ /函数将字符串转换为复杂类型.withColumn(“路径”,input_file_name) / / input_file_name用于提取输入文件的路径
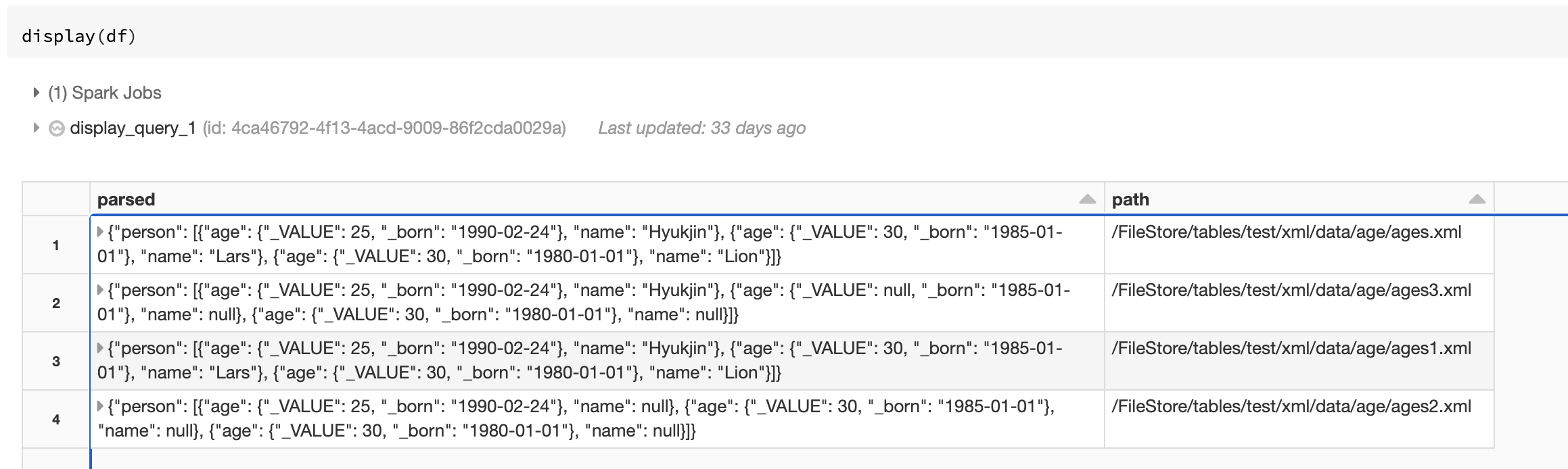
视图输出
一旦一切都设置,查看输出显示器(df)在一个笔记本上。
例如笔记本电脑
这个例子笔记本结合成一个单一的步骤,所有的功能的例子。
将其导入您的集群运行的例子。
流的XML例子笔记本
检查流的XML例子笔记本。