
问题
SparkTrials的延伸Hyperopt,它允许运行分布式引发工人。
当你开始一个MLflow运行嵌套= True在工人函数,结果应该是嵌套的父母下运行。
有时结果是不正确嵌套的父母下运行,即使你跑SparkTrials嵌套= True在工人的功能。
例如:
%的python hyperopt进口fmin, tpe,惠普,试验,STATUS_OK def火车(params):“”一个例子训练方法,计算输入的平方。该方法将被传递给“hyperopt.fmin ()”。:param参数:hyperparameters。它的结构是一致的搜索空间是如何定义的。见下文。:返回:dict字段“损失”(标量损失)和“状态”(成功/失败运行状态)与mlflow”“”。start_run (run_name = inner_run,嵌套= True)运行:x =参数返回{“损失”:x * * 2,“状态”:STATUS_OK}与mlflow.start_run (run_name = outer_run_with_sparktrials): spark_trials_run_id = mlflow.active_run () .info.run_id argmin = fmin (fn =火车,空间= search_space算法=藻类,max_evals = 16,试验= spark_trials)
预期结果:
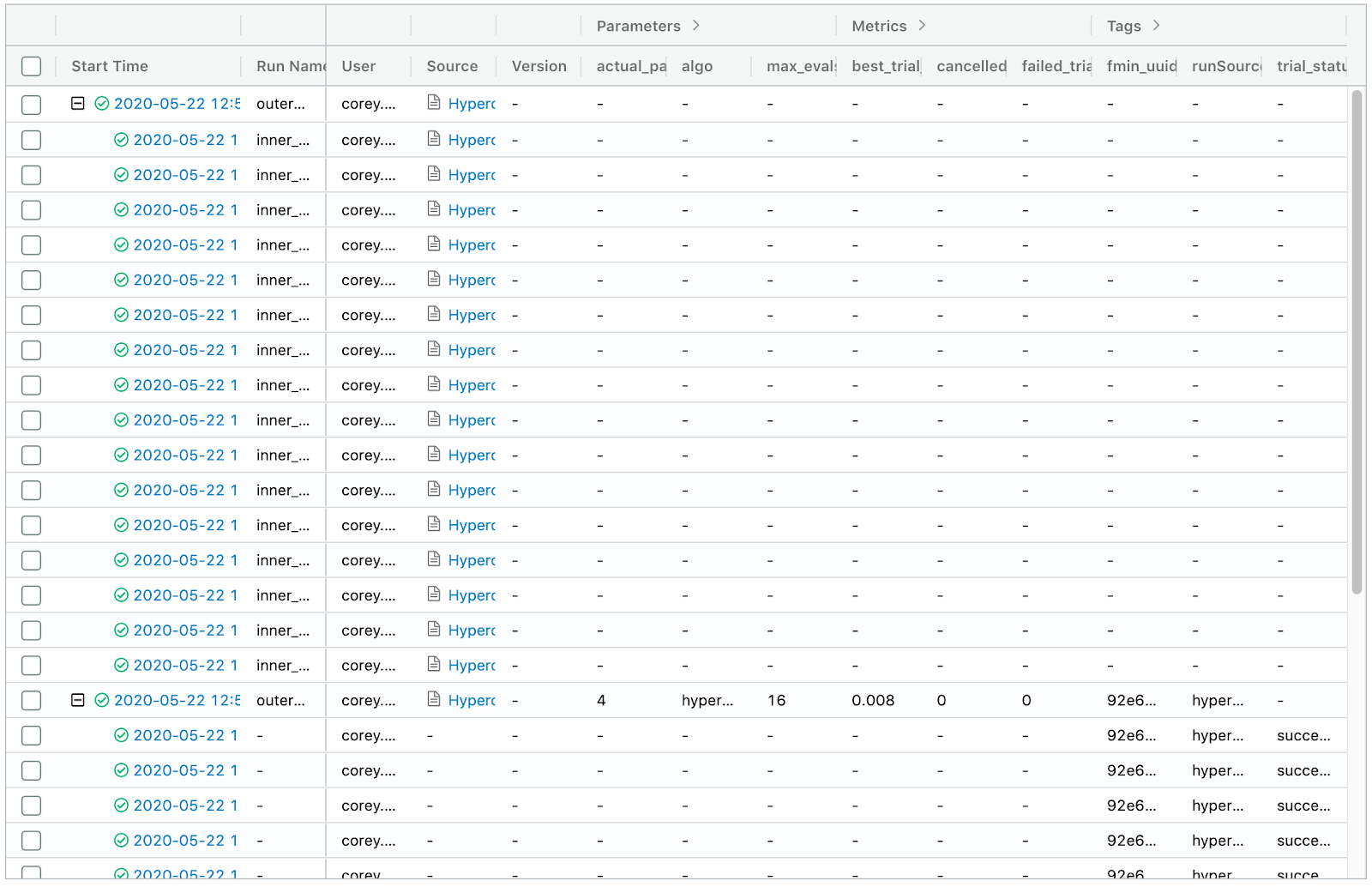
实际结果:
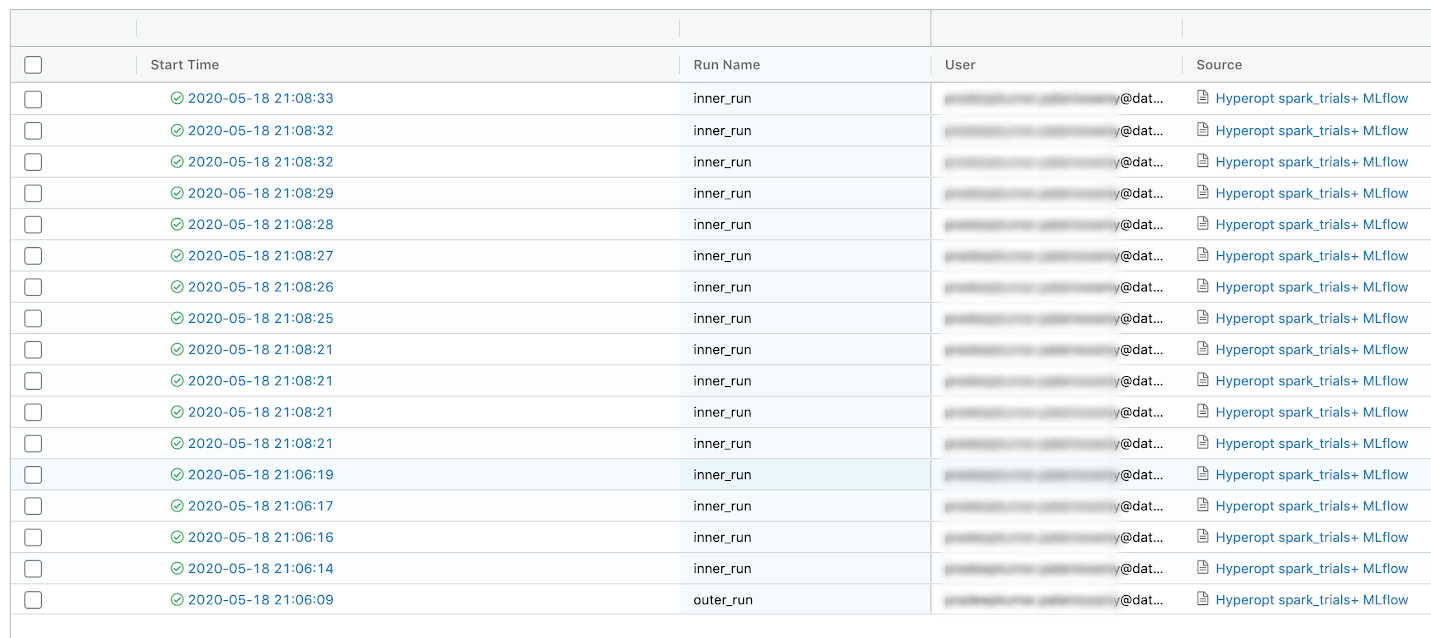
导致
Hypebob下载地址ropt的开源版本不支持所需的功能必须正常巢SparkTrials MLflow砖上运行。
解决方案
砖运行时对机器学习与附加功能包括一个内部叉Hyperopt。如果你想使用SparkTrials,您应该使用砖为机器学习,而不是运行时安装Hyperopt手动从开源库。