
如果你有一个高度定制的砖集群,您可能想要复制它,使用它为其他项目。当你克隆一个集群,只有Apache火花复制配置和其他集群配置信息。默认安装库不是副本。
复制安装库,您可以运行一个Python脚本后克隆集群。
指令
识别源和目标
源集群是集群你想复制。
你想要的目标集群是集群复制。
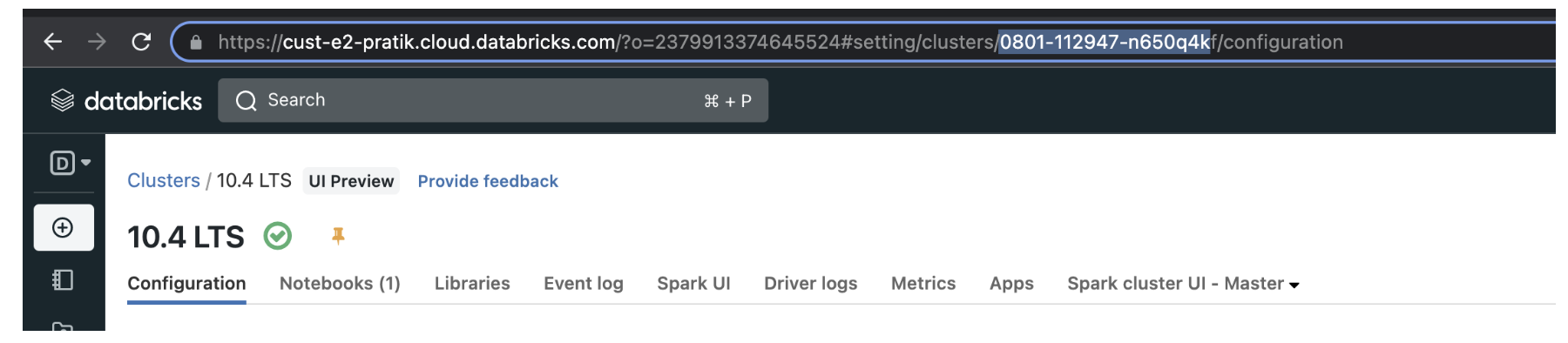
你可以找到的< source-cluster-id >和< target-cluster-id >通过选择工作区中的集群,然后寻找集群ID在URL中。
https:// < databricks-instance > / # /设置/集群/ < cluster-id >
在下面的截图,集群ID0801 - 112947 n650q4k。
创建一个砖个人访问令牌
遵循个人用户访问令牌(AWS|Azure|GCP)的文档创建一个个人访问令牌。
创建一个秘密范围
遵循创建一个Databricks-backed秘密范围(AWS|Azure|GCP)文档创建秘密范围。
你的个人访问令牌和砖实例存储在保密范围
遵循创建一个秘密Databricks-backed范围(AWS|Azure|GCP)文档存储个人访问令牌和砖实例创建新的秘密范围内你的秘密。
砖实例是工作空间的主机名,例如,xxxxx.cloud.www.neidfyre.com。
使用Python脚本克隆安装的库
您可以使用这个例子Python脚本安装库集群从源复制到目标集群。
你需要运行脚本之前替换以下值:
- < scope-name >——你的名字包含秘密范围。
- < secret-name-1 >——秘密的名字会握着你的砖实例。
- < secret-name-2 >——秘密的名称保存你的个人访问令牌。
- < source-cluster-id >——集群的集群ID你想复制。
- < target-cluster-id >——集群的集群ID你想复制。
示例脚本复制到一个笔记本,附加到运行集群在工作区中。
% python导入请求从pyspark.sql进口json导入时间。导入类型(StructField, StringType StructType, IntegerType) API_URL = dbutils.secrets。get(范围= " < scope-name >”,关键= < secret-name1 >) #https://xxxxx.cloud.www.neidfyre.com/令牌= dbutils.secrets。get(范围= " < scope-name >”,关键= < secret-name2 >) #砖拍牌source_cluster_id = < source-cluster-id >“target_cluster_id = source_cluster_api_url = API_URL +“< target-cluster-id > / api / 2.0 /图书馆/集群状态?cluster_id = " + = < source-cluster-id >响应请求。get (source_cluster_api_url header ={“授权”:“持票人”+ <标记>})库=[]的library_info response.json () [' library_statuses ']: lib_type = library_info[‘图书馆’]状态= library_info(的地位)libraries.append (lib_type)打印(“从源代码库集群(“+ source_cluster_id +”):“+ str(库)+“\ n”) target_cluster_api_url = API_URL + / api / 2.0 /图书馆/安装“target_lib_install_payload = json。转储({cluster_id: target_cluster_id,“库”:库})打印(“安装在集群目标库(“+ source_cluster_id +”)与有效载荷:”+ str (target_lib_install_payload) + " \ n ") =响应请求。帖子(target_cluster_api_url header ={“授权”:“持票人”+牌},data = target_lib_install_payload)如果反应。status_code = = 200:打印(“安装请求成功。响应代码:“+ str (response.status_code))else: print("Installation failed.Response code :"+str(response.status_code))
测试目标集群
脚本运行完成后,启动目标集群,并验证库复制了。