
问题
你想读兽人文件从一个目录,当你得到一个错误信息:
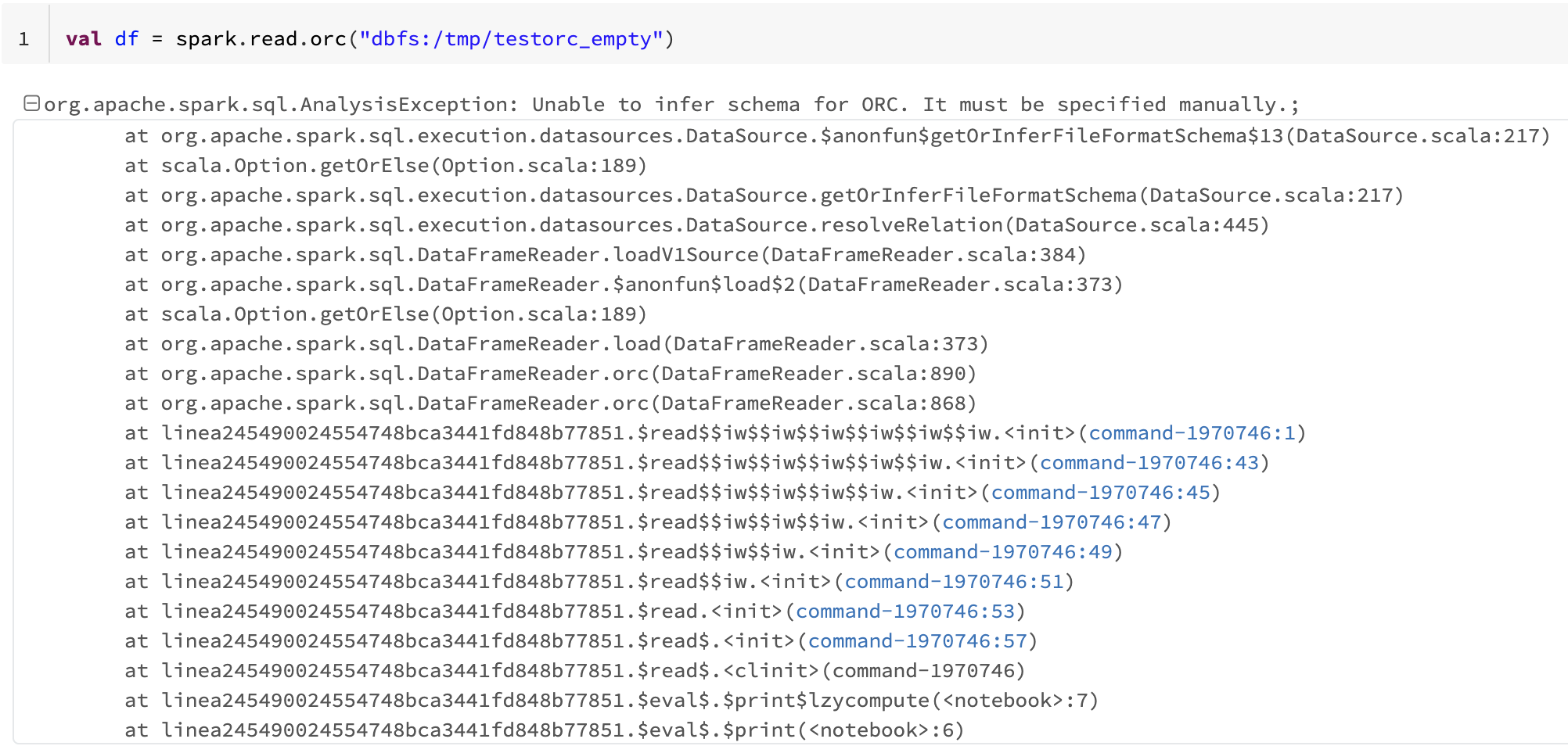
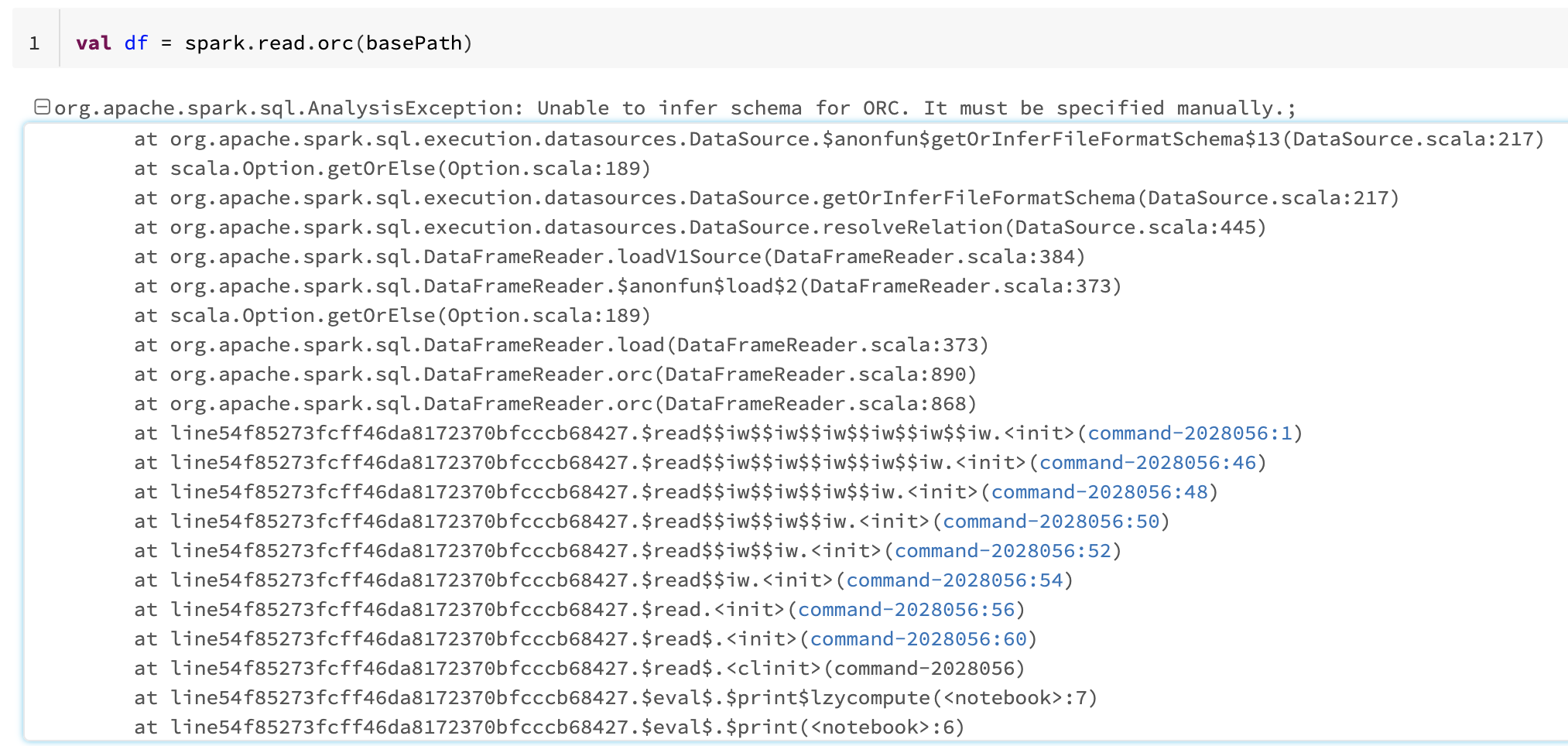
org.apache.spark.sql。一个alysisException: Unable to infer schema for ORC. It must be specified manually.
导致
一个无法推断出兽人的模式发生错误时的模式没有定义和Apache火花不能推断出模式由于:
- 一个空的目录。
- 使用的基本路径,而不是完整的路径文件包含兽人当有多个文件夹文件。
空目录的例子
- 创建一个空的目录/ tmp / testorc_empty。
% sh mkdir / dbfs / tmp / testorc_empty
- 尝试读取目录。
val df = spark.read.orc (“dbfs: / tmp / testorc_empty”)
- 读失败的无法推断出兽人的模式错误。
基本路径的例子
当只给出了基本路径(而不是完整的路径),有多个文件夹包含兽人文件,阅读尝试返回错误:无法推断出兽人的模式。
- 创建多个文件夹下/ tmp / testorc。
进口org.apache.hadoop.fs。路径val basePath = " dbfs: / tmp / testorc”spark.range (1) .toDF .write (“a”)。兽人(新路径(basePath,“第一”).toString) spark.range (1、2) .toDF .write (“a”)。兽人(新路径(basePath,“第二”).toString) spark.range (2、3) .toDF .write (“a”)。兽人(新路径(basePath,“第三”).toString)
- 尝试读取目录/ tmp / testorc。
val df = spark.read.orc (basePath)
- 读失败的无法推断出方案兽人错误。
解决方案
空目录的解决方案
- 创建一个空的目录/ tmp / testorc_empty。
% sh mkdir / dbfs / tmp / testorc_empty
- 包括模式当你试图阅读目录。
val df_schema = spark.read。模式(“int”) .orc (“dbfs: / tmp / testorc_empty”)
- 阅读尝试不返回一个错误。

基本路径解决方案
- 创建多个文件夹下/ tmp / testorc。
进口org.apache.hadoop.fs。路径val basePath = " dbfs: / tmp / testorc”spark.range (1) .toDF .write (“a”)。兽人(新路径(basePath first1) .toString) spark.range (1、2) .toDF .write (“a”)。兽人(新路径(basePath second2) .toString) spark.range (2、3) .toDF .write (“a”)。兽人(新路径(basePath third3) .toString)
- 包括模式和子文件夹的完整路径,当您试图读取目录。在这个例子中,我们使用文件夹的路径/ third3 /。
val dfWithSchema = spark.read。模式(“长”)。兽人(basePath + / third3 /)
- 阅读尝试不返回一个错误。

