
当您创建一个集群,人均砖发射一个Apache火花executor实例的节点,和执行程序使用的所有核心节点。在某些情况下,例如,如果你想运行非线程安全的JNI库,您可能需要一个执行者,只有一个核心或任务槽,和不会尝试运行并发任务。在这种情况下,多个executor实例运行在一个工作节点,每个执行器只有一个核心。
如果你运行多个执行者,你增加JVM开销和降低总体可用内存进行处理。
开始单核执行人工人节点,配置的两个属性火花配置:
- spark.executor.cores
- spark.executor.memory
房地产spark.executor.cores指定每个执行者的核数。将此属性设置为1。
房地产spark.executor.memory指定数量的内存分配到每一个执行者。这对执行人必须设置足够高的正常功能,但足够低,允许所有核心。
AWS
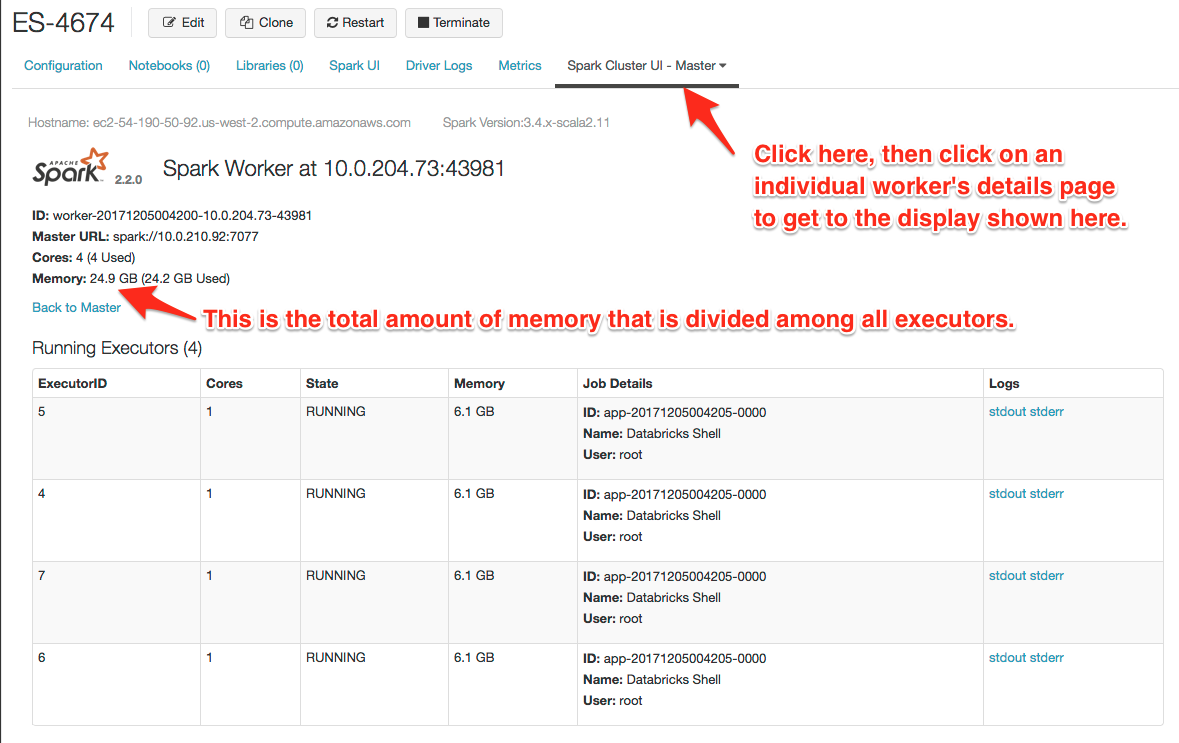
例如,一个i3.xlarge节点,30.5 GB的内存,显示可用内存为24.9 GB。选择适合的价值时,可用内存的数量乘以执行人。您可能需要设置一个值,允许一些开销。例如,设置spark.executor.cores来1和spark.executor.memory来6克:
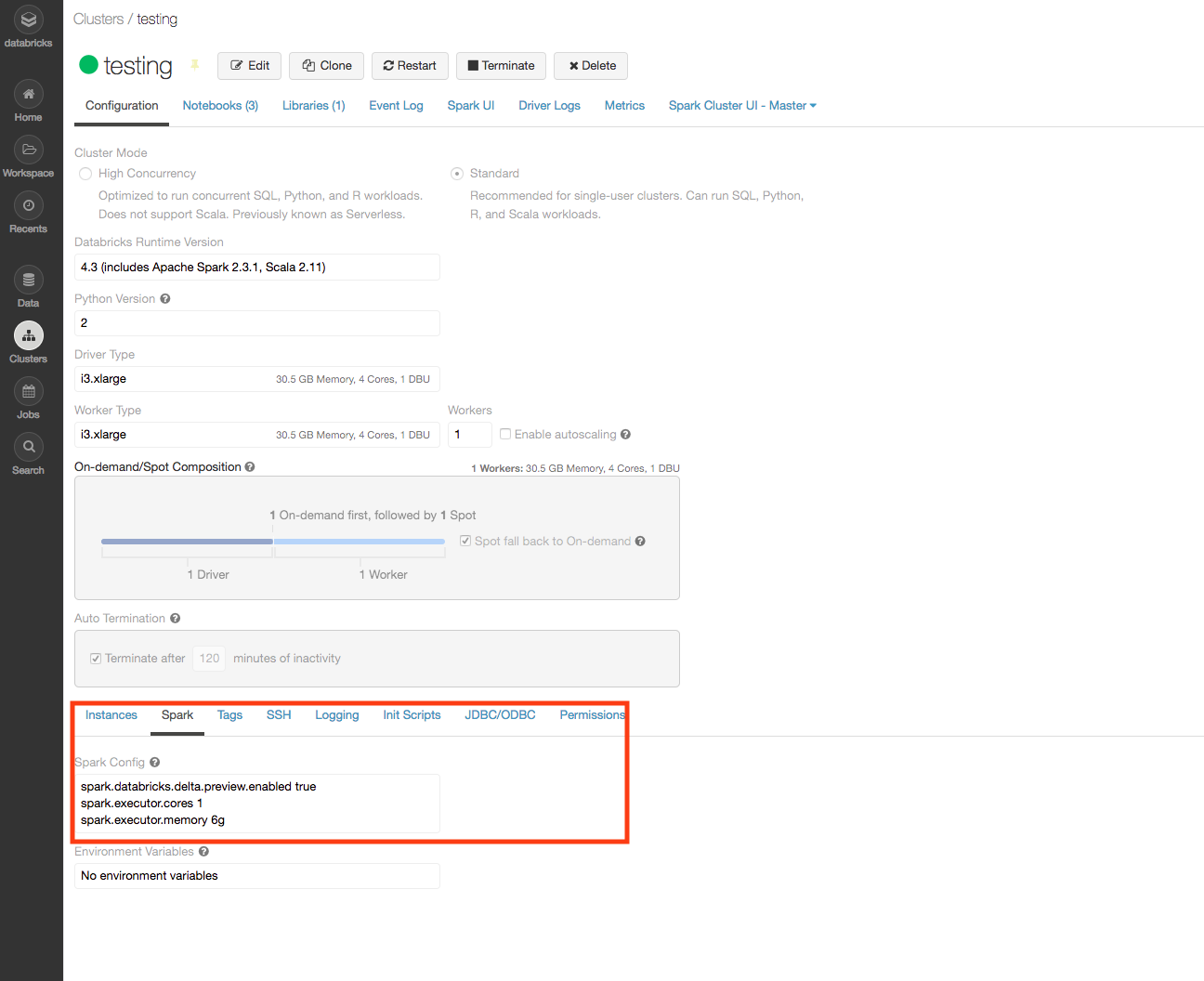
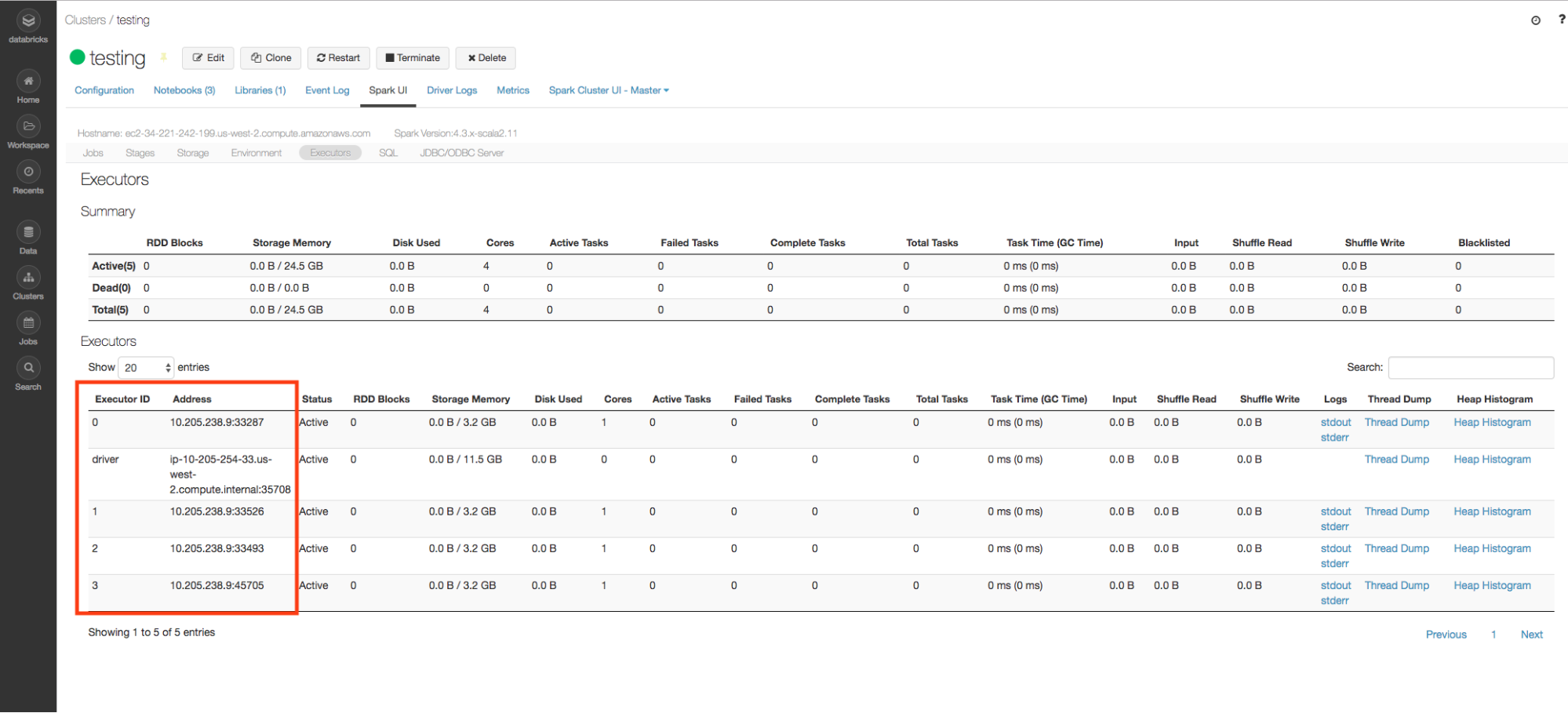
的i3.xlarge实例类型有4个核心,所以4执行人上创建节点,每6 GB的内存。
GCP
例如,n1-highmem-4工作者节点有26个GB的内存总量,但只有15.3 GB的可用内存一旦集群运行。
使用一个例子火花配置价值,我们的核心价值1和5 GB的内存分配给每一个执行者。
spark.executor.cores1spark.executor.memory5g
一旦集群开始,工人每个有4个核心节点,但只有3。有三个执行人,每个工作节点上5 GB的内存。这是一个共有15 GB的内存使用。
第四核心永远旋转起来,因为没有足够的内存分配。
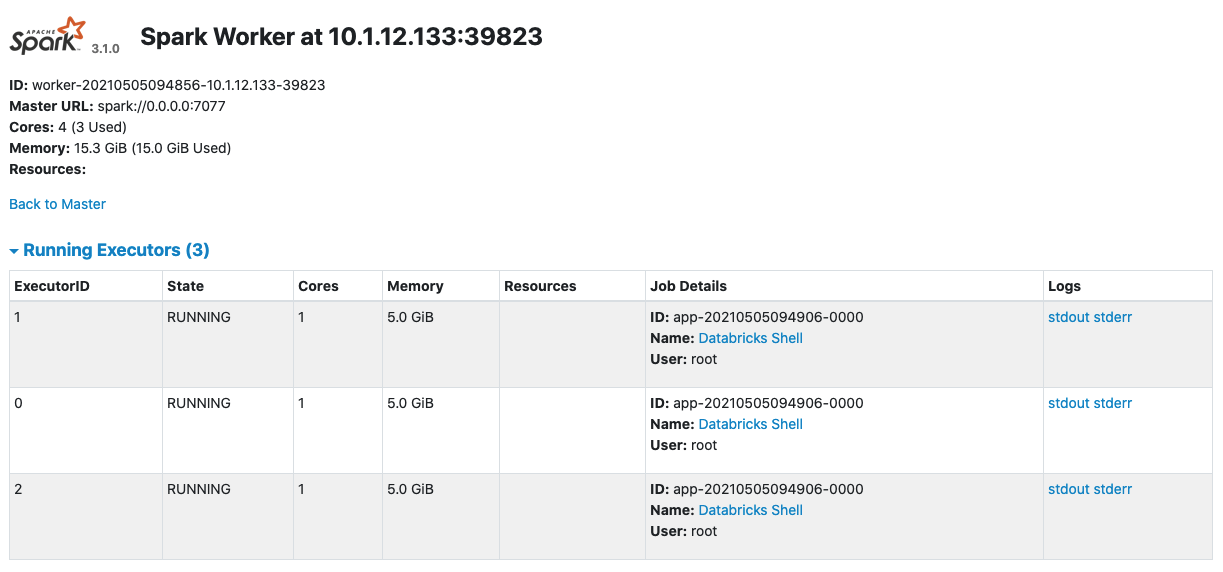
你必须平衡选择实例类型的内存要求每个执行者为了最大化的使用每一个核心工作节点。
删除