在砖笔记本的开发代码
这个页面描述如何开发代码在砖笔记本,包括自动完成,自动格式化Python和SQL,结合Python和SQL的笔记本,笔记本修订历史和跟踪。
更多细节关于先进与编辑功能,如自动完成、变量选择、multi-cursor支持,并排的差别,看到使用砖笔记本和文件的编辑器。
浏览数据
预览
这个特性是在公共预览。
使用浏览器的模式探索表和卷的笔记本。点击![]() 在左边的笔记本打开浏览器模式。
在左边的笔记本打开浏览器模式。
的为你按钮显示只有那些表,你用于当前会话或先前标记为一个最喜欢的。
文本输入过滤器框,显示会发生相应变化,也就是只显示那些物品包含文本的类型。只有当前打开的项目或当前会话中打开出现。的过滤器框不做一个完整的搜索目录的模式,可用于笔记本和表。
打开 烤肉串菜单,将鼠标停留在项的名称如图所示:
烤肉串菜单,将鼠标停留在项的名称如图所示:
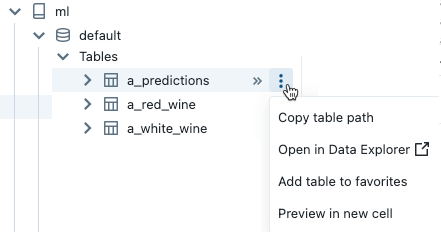
如果项目是一个表,你可以做以下几点:
自动创建并运行一个细胞显示表中的数据的预览。选择预览新细胞从表的烤肉串菜单。
查看目录,在数据浏览模式,或表。选择在数据浏览器烤肉串的菜单。将打开一个新标签页显示所选择的项。
获得一个目录的路径、模式或表。选择复制路径…从烤肉菜单项。
添加一个表。选择将表添加到收藏夹从表的烤肉串菜单。
如果项目是一个目录,模式,或体积,你可以复制项的路径或在数据浏览器打开它。
插入一个表或列名称直接进入细胞:
点击你的鼠标在细胞位置你想输入名称。
移动光标时,表名或列名在浏览器模式。
点击双箭头
 出现在正确的物品的名字。
出现在正确的物品的名字。
查找和替换文本
查找和替换文本在一个笔记本,选择编辑>查找和替换。当前突出显示匹配的橙色和所有其他比赛用黄色突出显示。
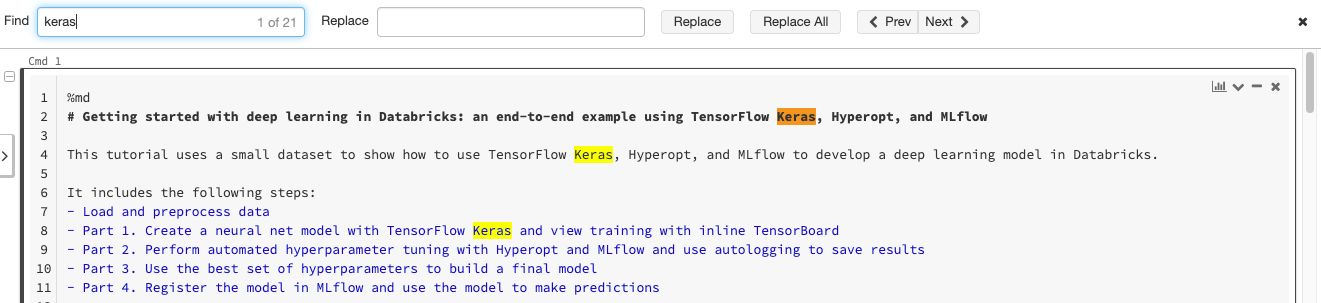
替换当前匹配,点击取代。替换所有匹配的笔记本,点击替换所有。
比赛之间移动,单击上一页和下一个按钮。你也可以按shift + enter和输入去前一个和后一个比赛,分别。
关闭查找和替换工具,单击![]() 或按esc。
或按esc。
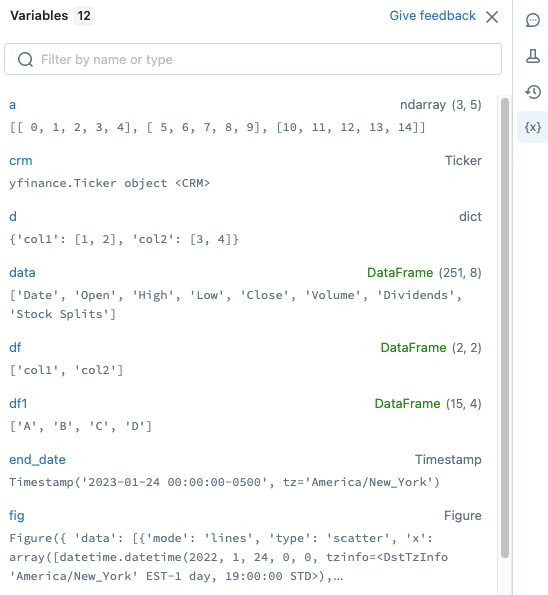
变量的探险家
与砖运行时的12.1及以上,可以直接观察到当前的Python变量在笔记本上的UI。
打开变量浏览器,点击![]() 在正确的栏。变量explorer打开时,显示值和数据类型,包括形状,每个变量当前定义的笔记本。(形状PySpark dataframe”吗?”,因为计算形状可以计算昂贵。)
在正确的栏。变量explorer打开时,显示值和数据类型,包括形状,每个变量当前定义的笔记本。(形状PySpark dataframe”吗?”,因为计算形状可以计算昂贵。)
过滤显示,搜索框中输入文本。自动过滤列表类型。
变量的值会自动更新你的笔记本电池。
模块化代码
预览
这个特性是在公共预览。
砖运行时的11.2及以上,您可以创建和管理源代码文件的砖工作区,然后将这些文件导入到你的笔记本电脑。
在使用源代码文件的更多信息,见砖笔记本之间共享代码和使用Python和R模块。
运行选中的文本
你可以强调代码或SQL语句在笔记本电池和运行选择。这是非常有用的,当你想在代码和快速迭代查询。
强调你想要运行的线路。
选择选择Run > Run文本或使用键盘快捷键
Ctrl+转变+输入。如果没有文本突出显示,运行选中的文本执行当前行。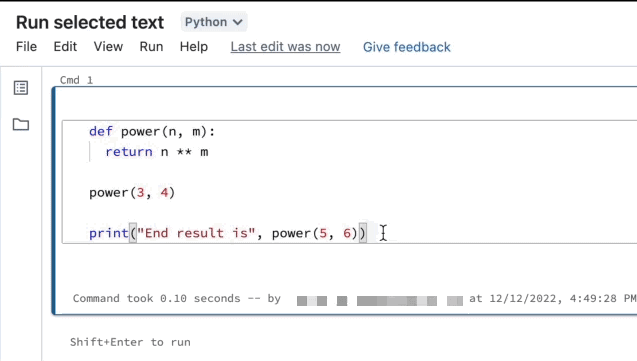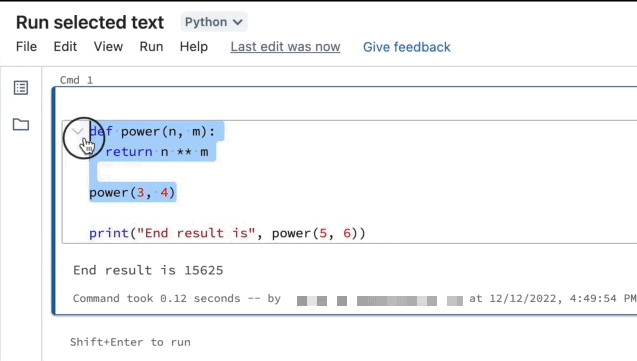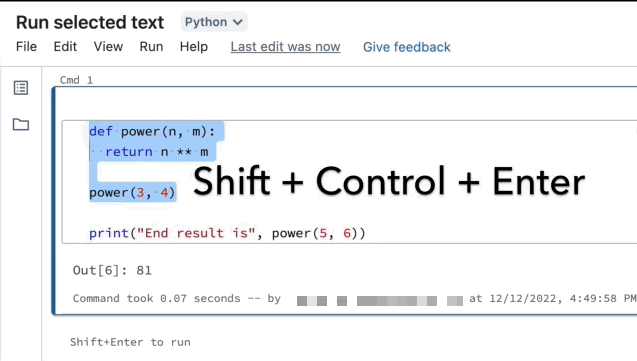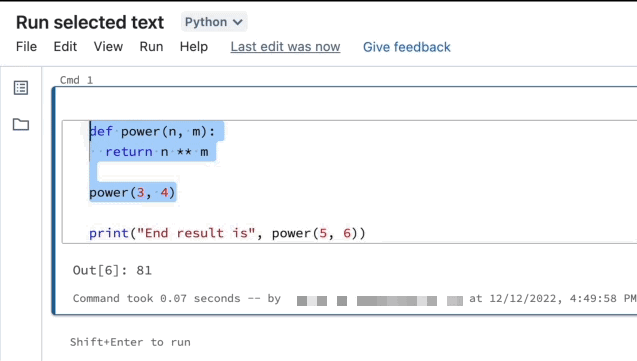

如果您使用的是混合语言在一个单元中,你必须包括% <语言>行选择。
运行选中的文本也执行倒塌的代码,如果有任何选择突出显示。
特殊的细胞命令等运行%,%皮普,% sh都受支持。
你不能使用运行选中的文本细胞上有多个输出选项卡(即细胞,你定义了一个数据概要或可视化)。
格式代码细胞
砖提供了工具,允许你格式Python和SQL代码快速轻松地在笔记本电池。这些工具减少努力保持代码格式化并帮助在整个笔记本电脑执行相同的编码标准。
格式Python细胞
预览
这个特性是在公共预览。
砖支持Python代码的格式使用黑色的在笔记本上。笔记本必须连接到一个集群黑色的和tokenize-rt安装Python包,黑色的格式化程序执行在集群上的笔记本相连。
砖运行时的11.2及以上,砖预设的黑色的和tokenize-rt。你可以直接使用格式化程序,而不需要安装这些库。
砖运行时的11.1及以下,您必须安装黑色= = 22.3.0和tokenize-rt = = 4.2.1从PyPI上你的笔记本或集群使用Python格式化程序。你可以在你的笔记本上运行以下命令:
%皮普安装黑色的= =22.3.0标记- - - - - -rt= =4.2.1
或在集群上安装该库。
关于安装库的更多细节,请参阅Python环境管理。
在砖回购的文件和笔记本电脑,您可以配置Python格式化程序的基础上pyproject.toml文件。要使用该功能,创建一个pyproject.toml回购根目录中的文件,并根据配置它黑色的配置格式。编辑工具。黑色的] section in the file. The configuration is applied when you format any file and notebook in that Repo.
如何格式化Python和SQL细胞
你必须有可以编辑的权限笔记本上的格式代码。
你可以用以下方式触发格式化程序:
格式一个细胞
多个单元格式
选择多个单元然后选择编辑>格式细胞(s)。如果您选择超过一种语言的细胞,只格式化SQL和Python细胞。这包括那些使用
%的sql和% python。格式在笔记本上所有Python和SQL细胞
选择编辑>格式笔记本。如果你的笔记本包含不止一个语言,只格式化SQL和Python细胞。这包括那些使用
%的sql和% python。
代码格式化的局限性
黑色的执行PEP 8标准4空间缩进。压痕是不可配置的。
格式不支持嵌入式Python字符串在SQL UDF。同样,格式化SQL字符串里面不支持Python UDF。
版本历史
砖笔记本维护笔记本的历史版本,允许您查看和恢复之前的快照的笔记本。在版本可以执行以下操作:添加评论,恢复和删除版本,和清晰的版本历史。
你也可以同步与远程数据砖Git存储库。
访问笔记本版本,点击 正确的栏。笔记本出现修订历史。您也可以选择文件>版本历史。
正确的栏。笔记本出现修订历史。您也可以选择文件>版本历史。



代码语言在笔记本

混合语言
默认情况下,笔记本电脑的电池使用默认的语言。你可以覆盖默认的语言在一个单元中通过单击语言按钮,从下拉菜单选择一种语言。
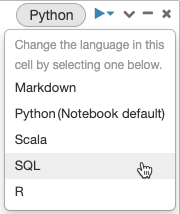
或者,您可以使用语言神奇的命令% <语言>在一个细胞的开始。支持的神奇的命令是:% python,r %,% scala,%的sql。
请注意
当你调用一个语言神奇的命令,该命令派往的REPL执行上下文的笔记本。变量定义在一个语言(语言),因此在REPL REPL的不可用另一种语言。repl只能通过外部资源(如文件共享状态在对象存储DBFS或对象。
笔记本也支持一些辅助魔法命令:
% sh:允许您运行shell代码在你的笔记本上。失败的细胞如果shell命令有一个非零退出状态,添加- e选择。该命令只运行在Apache火花司机,而不是工人。所有节点上运行shell命令,使用一个init脚本。% fs:允许您使用dbutils文件系统命令。例如,运行dbutils.fs.ls命令列表文件,您可以指定% fsls代替。有关更多信息,请参见如何处理文件数据砖吗。%医学博士:可以包括各种类型的文档,包括文本、图片、和数学公式和方程。请参阅下一节。
SQL语法突出显示和自动完成在Python命令
语法高亮显示和SQL自动完成可以使用SQL在Python命令时,如在吗spark.sql命令。
探索Python中的SQL细胞结果笔记本使用Python
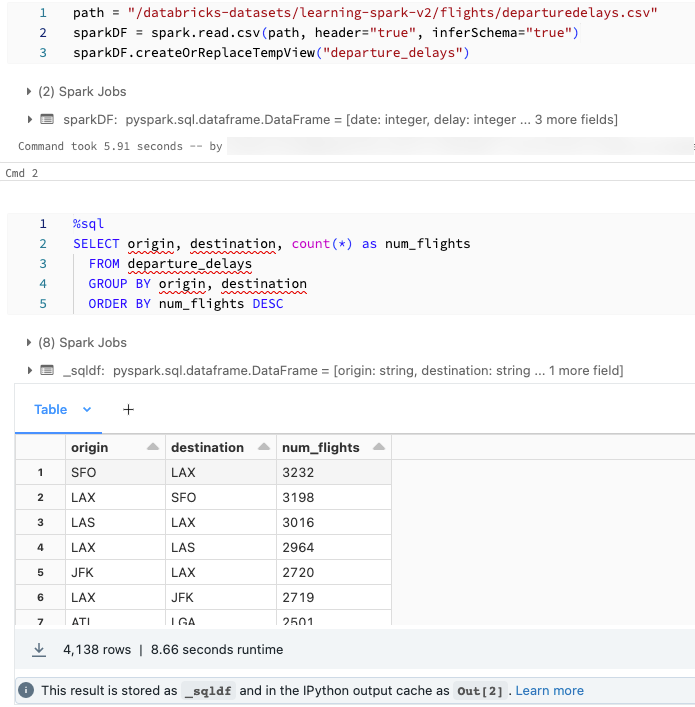
您可能想要使用SQL数据加载使用Python和探索它。在砖Python的笔记本,表结果从一个SQL语言细胞自动作为一个Python DataFrame分配给变量_sqldf。
在砖运行时的13.0及以上,您也可以访问DataFrame结果使用IPython的输出缓存系统。提示柜台出现在底部的输出消息显示细胞的结果。对于示例所示,你会参考的结果出[2]。
请注意
的变量
_sqldf可能每次都重新分配吗%的sql电池运行。避免失去参考DataFrame结果,将其分配给一个新的变量名之前运行%的sql细胞:new_dataframe_name=_sqldf
如果查询使用小部件参数化的结果并不像Python DataFrame可用。
如果查询使用关键词
缓存表或UNCACHE表,结果不能作为一个Python DataFrame。
屏幕截图显示了一个例子:
并行执行SQL细胞
当一个命令运行时和你的笔记本电脑连接到集群互动,您可以运行一个SQL细胞同时与当前命令。执行SQL细胞在一个新的、并行会话。
并行执行细胞:
运行单元。
点击现在运行。细胞是立即执行。

因为细胞是运行在一个新的会话,临时观点,udf,隐式Python DataFrame(_sqldf)不支持并行执行的细胞。此外,默认目录和数据库名称并行执行期间使用。如果您的代码是指一个表在不同的目录或数据库中,您必须指定表名使用三级名称空间(“目录”,“模式”。“表”)。
显示图像
存储在显示图像FileStore使用语法:
% md ! (测试)(文件/ image.png)
例如,假设您有砖FileStore标志图像文件:
dbfs ls dbfs: / FileStore /
databricks-logo-mobile.png
当你在减价细胞包括以下代码:

在细胞图像呈现:

显示数学公式
笔记本电脑支持KaTeX显示数学公式和方程。例如,
% md \ \ c = \ \ \ \下午√{b ^ ^ 2 + 2} \ \) \ \ b (a {_i} {_j} = {_i} {_j} \ \) $ $ c = \ \ \ \下午sqrt {b ^ ^ 2 + 2} $ $ \ \ [{_i} {_j} = b {_i} {_j} \ \]
显示为:
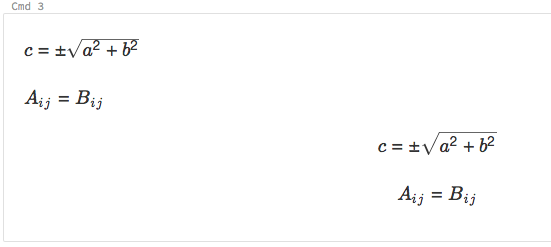
和
% md \ \ (f(\β)= -Y_t ^ T X_t \β+ \和日志(1 + {e} ^{间t \子弹\β})+ \压裂{1}{2}\δt S_t ^ ^{1} \三角洲\ \)\ \(\δ=(β\ \ mu_ {t - 1}) \ \)
显示为:
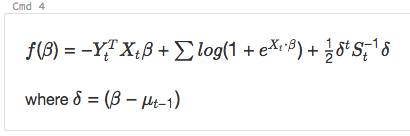
包括HTML
可以通过使用HTML包含在一个笔记本的功能displayHTML。看到HTML、D3和SVG的笔记本对于如何做到这一点的一个例子。
请注意
的displayHTMLiframe是服务的领域databricksusercontent.com和iframe沙箱包括allow-same-origin属性。databricksusercontent.com必须从浏览器访问。如果现在被你的公司网络,它必须被添加到一个允许列表。