谷歌云存储
介绍如何在Databricks中对谷歌GCS (Cloud Storage)表进行读写操作。如果要从GCS桶中读写,必须创建一个附加的服务帐户,并且在创建集群时必须将该桶与该服务帐户关联。
直接使用服务帐户电子邮件地址(推荐的方法)或为服务帐户生成的密钥连接到桶。
有关使用安装的GCS桶的文档,请参见在Databricks上挂载云对象存储.
步骤1:使用谷歌云控制台设置谷歌云服务账号
需要为Databricks集群创建一个服务帐号。我们建议给予此服务帐户执行其任务所需的最少权限。
重要的
服务帐户必须位于用于设置Databricks工作空间的谷歌Cloud项目中。
点击IAM和Admin在左侧导航窗格中。
点击服务帐户.
点击+创建服务账号.
输入服务帐户名称和描述。
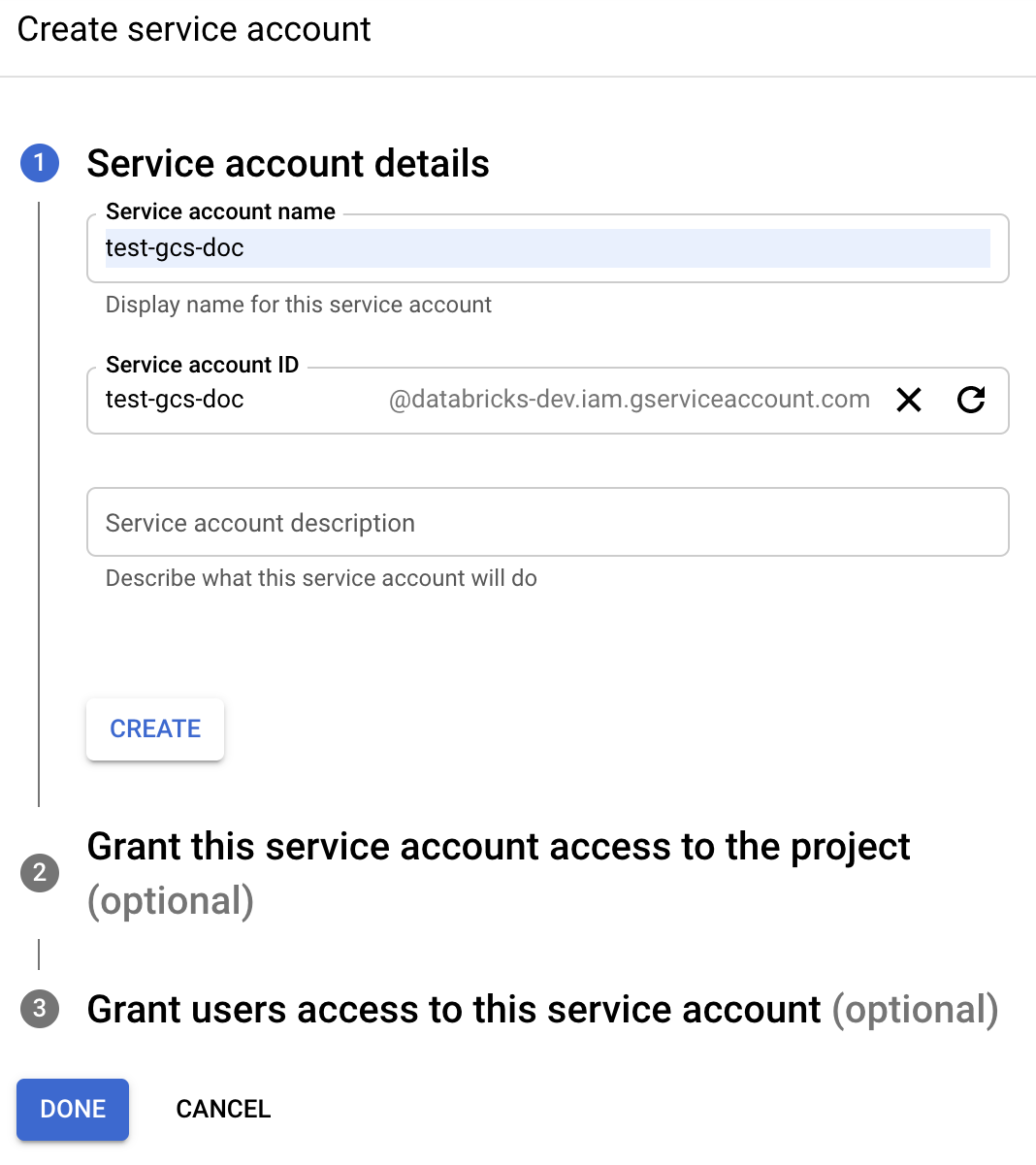
点击创建.
点击继续.
点击完成.
导航到谷歌云控制台服务帐户清单并选择一个服务帐户。
复制相关的电子邮件地址。在设置Databricks集群时将需要它。

步骤2:配置GCS桶
创建桶
如果你还没有桶,创建一个:
点击存储在左侧导航窗格中。
点击创建桶.
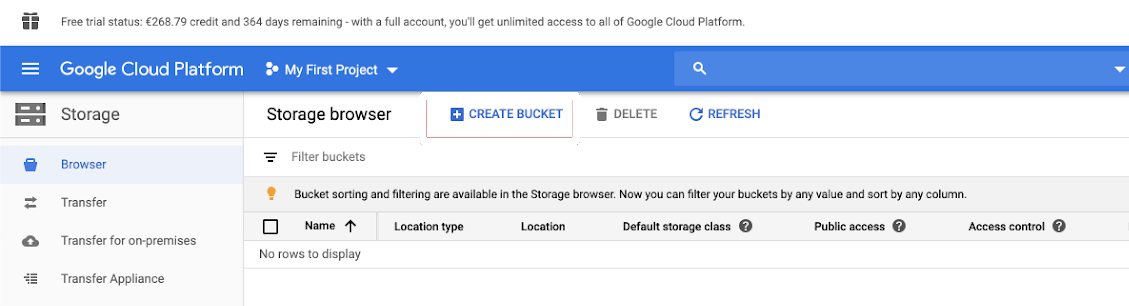
命名你的桶。选择一个符合谷歌的全局唯一的永久名称命名要求用于GCS桶。
重要的
要使用DBFS挂载,桶名不能包含下划线。
点击创建.

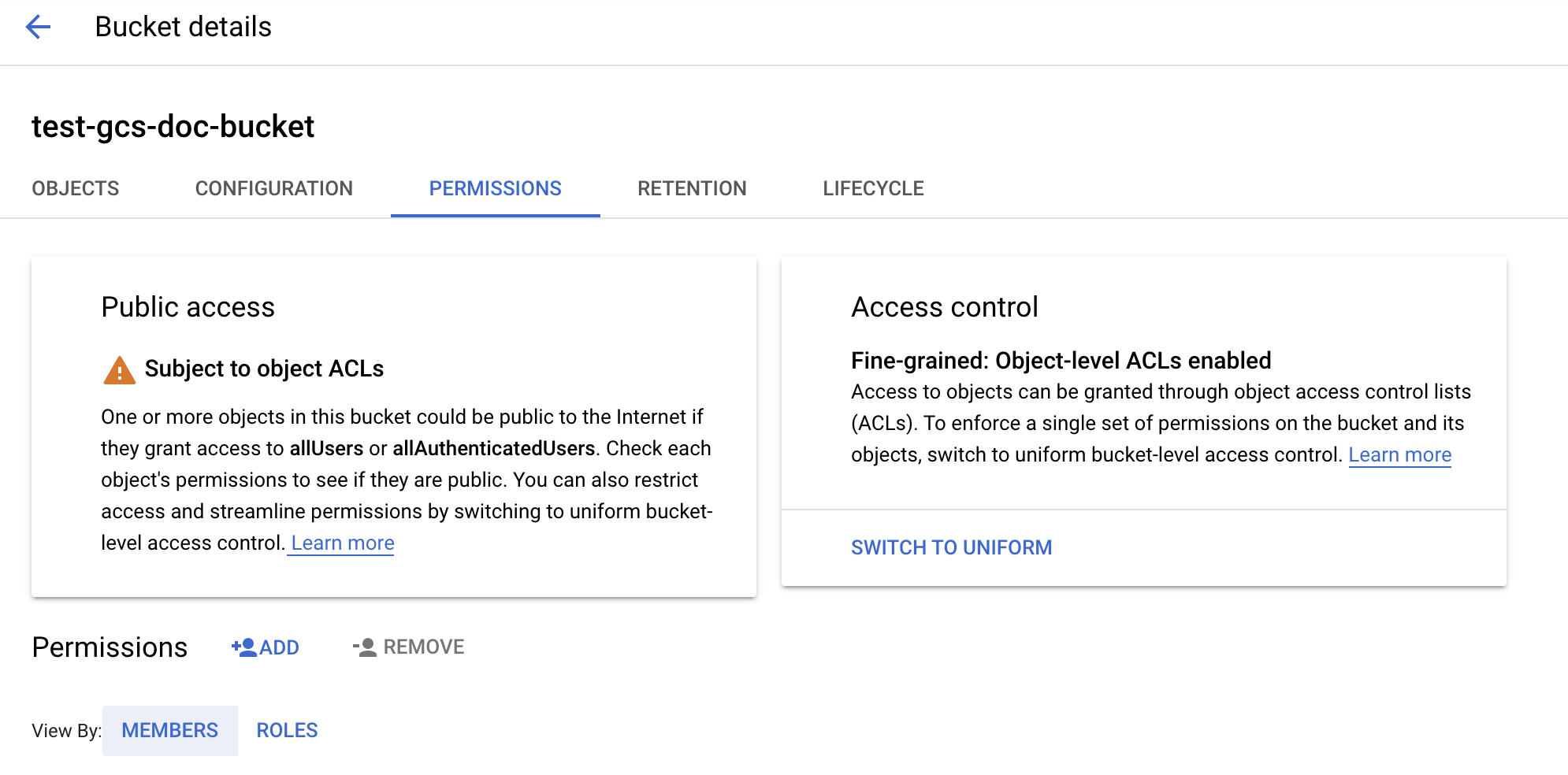
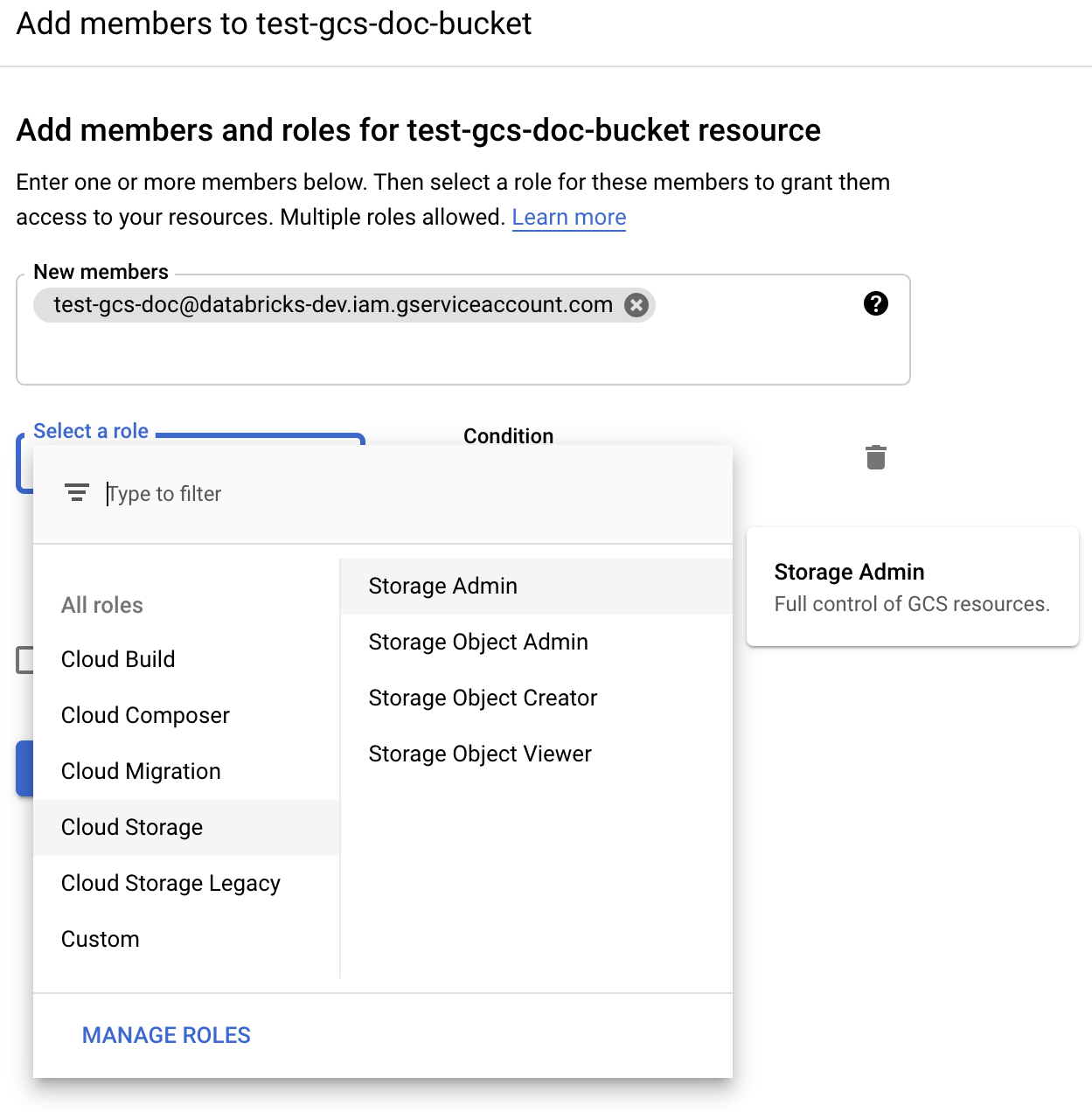
步骤3:设置Databricks集群
当你配置集群,扩大高级选项并设置谷歌业务帐号字段到您的服务帐户电子邮件地址。
直接访问GCS桶
若要直接读写桶,您可以设置服务帐户电子邮件地址或配置在您的火花配置.
步骤1:使用谷歌云控制台设置谷歌云服务账号
需要为Databricks集群创建一个服务帐号。Databricks建议给予该服务帐户执行其任务所需的最少权限。
点击IAM和Admin在左侧导航窗格中。
点击服务帐户.
点击+创建服务账号.
输入服务帐户名称和描述。
点击创建.
点击继续.
点击完成.
获取服务帐户的电子邮件地址或为服务帐户生成密钥。
请注意
Databricks建议使用服务帐户的电子邮件地址,因为不涉及密钥,因此没有泄露密钥的风险。使用键的一个原因是,如果服务帐户需要位于与创建工作区时使用的项目不同的谷歌Cloud项目中。
服务账号邮箱地址:进入谷歌云控制台服务帐户清单.选择业务帐户。复制与之相关的电子邮件地址。您将在集群设置页面中需要它。
重要的
如果使用服务帐户电子邮件地址方法,则服务帐户必须位于用于设置Databricks工作区的相同谷歌Cloud项目中。
关键:创建密钥。看到创建直接访问GCS桶的密钥.
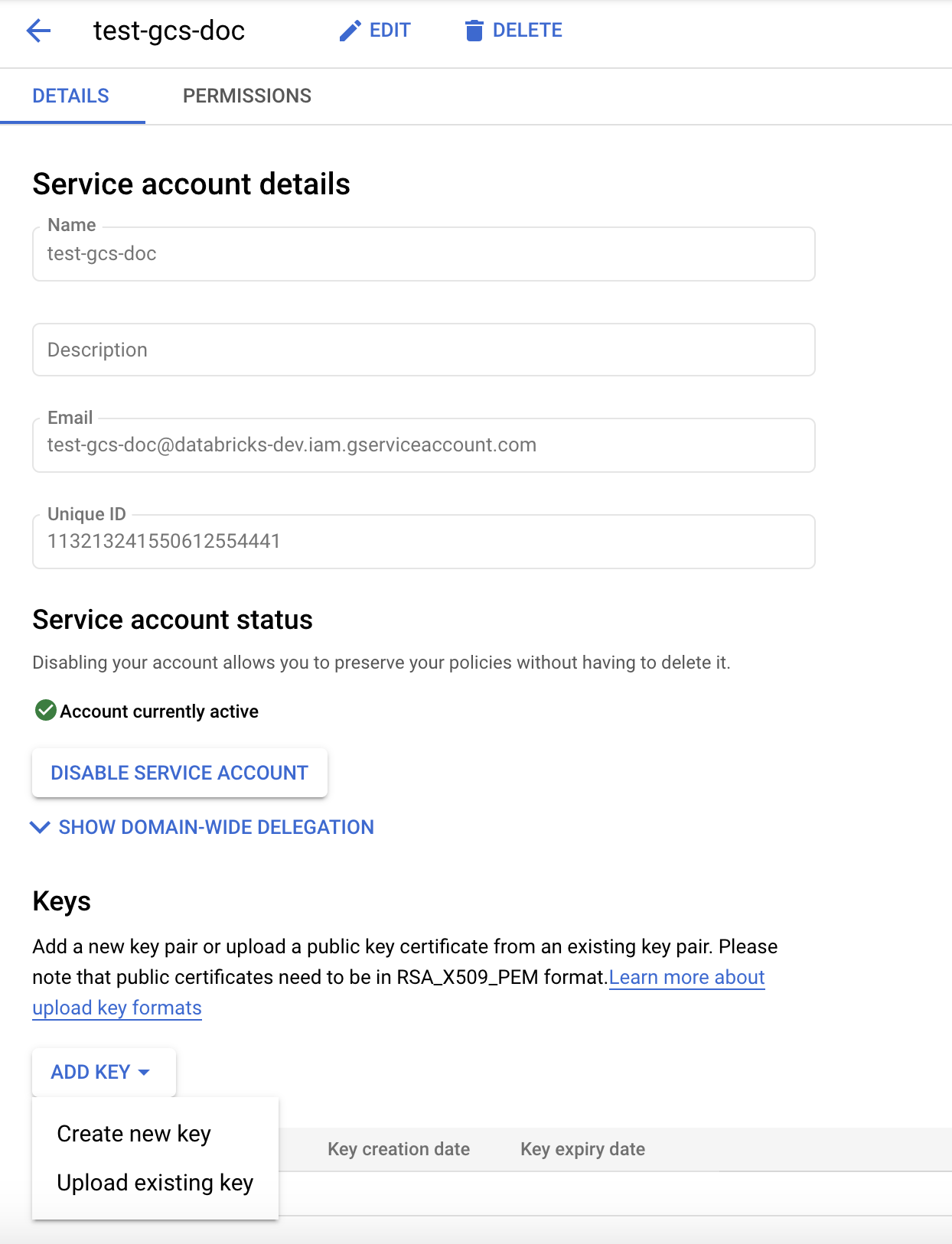
步骤3:设置Databricks集群
当你配置集群:
在Databricks运行时版本下拉,选择7.3 LTS或以上。
您可以使用服务帐户电子邮件地址或为服务帐户生成的密钥进行身份验证。
服务账号邮箱地址:扩大高级选项并设置谷歌业务帐号字段到您的服务帐户电子邮件地址。
关键:在火花配置页签,添加如下Spark配置。取代
< client_email >,< project_id >,< private_key >,< private_key_id >这些字段名称的值来自您的关键JSON文件。重要的
的值
< private_key_id >跨多行。粘贴整个私钥,包括开头和结尾的引号。spark.hadoop.google.cloud.auth.service.account.enable真实spark.hadoop.fs.gs.auth.service.account.email < client_email >spark.hadoop.fs.gs.project.id < project_id >spark.hadoop.fs.gs.auth.service.account.private.key < private_key >spark.hadoop.fs.gs.auth.service.account.private.key.id < private_key_id >
4 .使用方法
要从GCS桶中读取,可以使用任何支持的格式的Spark read命令,例如:
df=火花.读.格式(“铺”).负载(“gs: / / < bucket名> / <路径>”)
要写入GCS桶,可以使用Spark支持的任何格式的写命令,例如:
df.写.格式(“铺”).模式(“< >模式”).保存(“gs: / / < bucket名> / <路径>”)
取代< bucket名>中创建的bucket的名称步骤2:配置GCS桶.