创建一个集群
请注意
这些指令是为了统一目录启用工作区使用更新UI创建集群。切换到传统集群创建UI,点击用户界面预览在页面的顶部创建集群和切换设置。
不统一的文档目录遗留UI,明白了配置集群。比较新和遗留的集群类型,明白了集群UI变化和集群访问模式。
本文解释了可用的配置选项,当你创建和编辑数据砖集群。它着重于创建和编辑集群使用UI。其他方法,请参阅集群CLI(遗留),集群API,砖起程拓殖的提供者。
集群创建用户界面允许您选择集群配置细节,包括:
访问集群创建接口
使用用户界面创建一个集群,您必须在数据科学与工程或机器学习persona-based环境。使用角色切换器如果有必要的话)。
然后你可以:
点击
 计算在侧边栏创建计算在计算页面。
计算在侧边栏创建计算在计算页面。点击新>集群在侧边栏。
集群访问模式是什么?
集群访问模式是一个安全特性,决定谁可以使用一个集群和数据可以通过集群。当你创建任何集群在砖,你必须选择一个访问模式。
访问模式 |
对用户可见 |
加州大学的支持 |
支持的语言 |
笔记 |
|---|---|---|---|---|
单用户 |
总是 |
是的 |
Python, SQL, Scala, R |
可以分配给单个用户使用的。阅读从一个视图,你必须有 |
共享 |
总是(保费计划要求) |
是的 |
Python(砖运行时的11.1及以上),SQL |
可以使用多个用户与用户之间数据隔离。看到共享的局限性。 |
任何隔离共享 |
管理员可以隐藏这个集群类型执行用户隔离在管理页面设置。 |
没有 |
Python, SQL, Scala, R |
|
自定义 |
隐藏(所有新集群) |
没有 |
Python, SQL, Scala, R |
这个选项显示只有如果你有现有的集群,而无需指定的访问模式。 |
你可以升级现有集群的要求统一目录通过设置集群访问模式单用户或共享。有额外的访问模式的局限性对结构化流统一目录,看看结构化流媒体支持。
砖的运行时版本的
砖运行时核心组件的集合上运行您的集群。所有砖运行时版本包括Apache火花和添加组件和更新,提高可用性、性能和安全性。有关详细信息,请参见砖运行时。
您选择使用集群的运行时和版本砖的运行时版本的下拉当您创建或编辑一个集群。
集群节点类型
一个集群由一个驱动节点和零个或多个工作节点。你可以选择单独的云提供商为司机和工人节点实例类型,尽管默认情况下司机节点使用相同的实例类型工作节点。不同家庭的实例类型适合不同的用例,如内存密集型或计算密集型工作负载。
司机节点
司机节点维护状态信息的笔记本电脑连接到集群。司机节点还维护SparkContext,解释所有的命令你在集群上运行从一个笔记本和一个图书馆,并运行Apache主坐标的火花引发执行人。
司机节点类型的默认值是一样的工人节点类型。你可以选择一个更大的驱动节点类型和更多的内存,如果你正计划收集()大量的数据从引发工人和分析他们在笔记本上。
提示
因为司机节点维护的所有状态信息的笔记本电脑,确保分离未使用的笔记本从司机节点。
工作者节点
砖工节点运行正常运转所需的火花执行者和其他服务集群。当你分发工作负载与火花,所有的分布式处理发生在工作节点。砖一个人均执行器节点运行。因此,执行者和工人是交替使用的砖结构。
提示
火花运行工作,你至少需要一个工作节点。如果集群的工人为零,你可以运行non-Spark命令司机节点上,但火花命令将失败。
GPU实例类型
对于需求的高性能的计算有挑战性的任务,像那些与深度学习,砖支持集群加速的图形处理单元(gpu)。有关更多信息,请参见GPU-enabled集群。
与当地ssd集群实例类型
最新的实例类型列表,每一个的价格,和当地的ssd的大小,看到GCP定价估计量。
实例类型,当地ssd自动使用默认谷歌云服务器端加密和加密使用磁盘缓存改进的性能。缓存的大小在所有实例类型自动设置,所以你不需要显式地设置磁盘使用情况。
为您的集群配置本地ssd
您可以配置的本地ssd附着当您使用您的集群集群API创建集群。
配置本地ssd的数量,设置一个值local_ssd_count在gcp_attributes对象。每个实例类型只能支持一定数量的当地ssd。中指定的值local_ssd_count必须是有效的司机和工人实例类型。有关更多信息,请参见GCP的医生当地的ssd和机器类型。
集群规模和自动定量
当你创建一个砖集群,可以为集群提供一个固定数量的工人或提供的最小和最大数量的工人集群。
当你提供固定大小的集群,砖确保集群有指定数量的工人。当你为工人的数量,提供一系列砖选择适当数量的工人需要运行你的工作。这被称为自动定量。
与自动定量、动态砖是重新分配人员占你的工作的特点。某些部位的管道可能比其他人更计算要求,和砖自动添加额外的工人在这阶段的工作(并删除他们当他们不再需要)。
自动定量使它更容易实现集群利用率高,因为你不需要提供集群匹配工作负载。这尤其适用于负载的需求随时间变化(如每天探索过程中数据集),但它也能适用于一次性短工作负载的配置需求是未知的。自动定量因此提供了两个优点:
工作负载可以运行得更快而constant-sized under-provisioned集群。
自动定量集群静态大小的集群相比可以降低整体成本。
根据集群的常数大小和工作负载,自动定量给你其中的一个或两个同时受益。集群规模可以低于最小数量的工人时选择的云提供商终止实例。在这种情况下,砖不断重试重新供应实例为了维持最低的工人数量。
请注意
自动定量是不可用的spark-submit就业机会。
请注意
计算伸缩扩展限制了集群大小结构化流工作负载。砖建议使用三角洲表与增强的自动定量直播工作负载。看到增强的自动定量是多少?。
优化和标准自动定量
砖提供两种类型的集群节点自动定量:优化和标准。优化自动定量仅可在保费和企业的定价方案。看到bob体育客户端下载平台层。
优化的自动定量用于:
所有工作的集群
互动集群溢价或企业计划工作空间运行6.4 +砖运行时版本。
标准自动定量用于:
标准计划工作区
交互式运行在砖上的集群运行时6.3或更低水平。
如何优化自动定量的行为
尺度从最小到最大2步骤。
集群可以缩小,即使不是闲置,通过观察洗牌文件状态。
基于当前节点的比例尺度。
工作群,尺度下如果集群充分利用过去40秒。
通用的集群,尺度下如果集群充分利用过去150秒。
的
spark.databricks.aggressiveWindowDownS火花在几秒钟内配置属性指定集群频率使缩小规模的决定。持续增加的值会导致一个集群规模更慢。最大值是600。


本地磁盘加密
实例类型,当地ssd与默认谷歌云服务器端加密加密。看到与当地ssd集群实例类型。
集群的标签
集群标签允许您方便地监视各种团体所使用的云资源的成本在你的组织中。您可以指定标签作为键值对,当你创建一个集群,和砖这些标签适用于砖GKE集群上运行时豆荚和持久卷和DBU的使用报告。
的砖计费使用图表在账户控制台可以总使用个人标签。计费使用CSV报告从相同的下载页面还包括违约和自定义标记。标签也传播GKE和GCE标签。
为详细的信息关于池和集群标签类型一起工作,明白了使用集群和池监控使用标签
集群配置标签:
在标签节中,为每个定制标记添加一个键-值对。
点击添加。
谷歌云配置
当您配置一个集群的谷歌谷歌云实例可以指定特定于云的选项。
可用性区域
在集群配置页面,高级选项,您可以选择集群的可用性区域。此设置允许您指定使用哪个你想要的可用性区域集群。默认情况下,设置为可用性区域设置哈(高可用性)。
你也可以选择一个特定的区域或汽车。选择一个特定的区域主要是有用的,如果您的组织购买了保留的实例在特定的可用性区域。如果你选择汽车,可用性区域自动为您选择。
自动定量本地存储
谷歌云计算实例可以补充额外的存储在工人级别使用带状持续固态磁盘。
自动定量本地存储,数据砖监视器上可用的空闲磁盘空间集群的火花的工人。如果一个工人开始在磁盘上运行过低,砖自动调整大小的带状SSD PD之前耗尽了磁盘空间。Zonal-SSD PD卷附加到一个极限5 TB的总磁盘空间的每个实例(包括实例的本地存储)。
配置自动定量储存、选择启用自动定量本地存储。
默认配置存储
砖规定以下存储为每个工作节点:
一个100 GB的引导磁盘根卷使用的主机操作系统和砖内部服务。
当地使用的SSD引发工人。这个主机火花服务日志。配置本地ssd,明白了与当地ssd集群实例类型。
远程ssd存储自动定量时启用。这些从150 GB在创建并根据需要自动定量。
使用抢占的实例
一个抢占式虚拟机实例是一个实例,您可以创建和运行在一个低得多的价格要比普通的实例。然而,谷歌云可能会停止这些实例(抢占)如果需要访问这些资源其他任务。抢占式实例使用谷歌计算引擎能力过剩,所以他们的可用性随使用。
当你创建一个新的集群,您可以启用抢占的VM实例在两种不同的方式:
当你使用UI创建一个集群时,你可以点击抢占式实例旁边的工作类型细节。
当你使用UI创建一个实例池,您可以设置随需应变/抢占式来所有的抢占式,抢占式与后备GCP,或对需求的质量。如果抢占的VM实例并不可用,默认情况下,使用随需应变的VM实例集群将退回。配置默认行为,集
gcp_attributes.gcp_availability来PREEMPTIBLE_GCP或PREEMPTIBLE_WITH_FALLBACK_GCP。默认值是ON_DEMAND_GCP。
{“instance_pool_name”:“抢占的w / o后备API测试”,“node_type_id”:“n1-highmem-4”,“gcp_attributes”:{“gcp_availability”:“PREEMPTIBLE_GCP”}}
接下来,创建一个新的集群和设置池抢占式实例池。
火花配置
微调刺激就业,你可以提供自定义的火花配置属性在一个集群中配置。
在集群配置页面,单击高级选项切换。
单击火花选项卡。
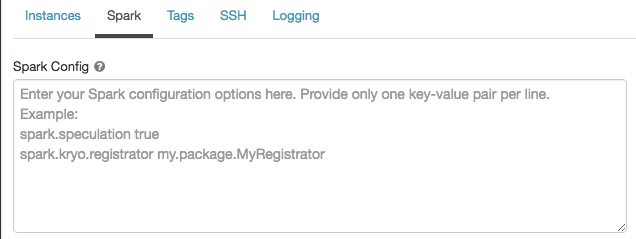
在火花配置进入配置属性,每行一个键-值对。

当您配置集群使用集群API,设置火花属性spark_conf字段创建新集群API或更新集群配置API。
执行火花在集群配置,工作空间管理员可以使用集群政策。
检索一个火花配置属性从一个秘密
砖建议存储敏感信息,比如密码,秘密而不是明文。引用一个秘密的火花配置,使用下面的语法:
火花。<属性名>{{秘密/ < scope-name > / <秘密名字>}}
例如,设置一个火花配置属性密码秘密存储的值秘密/ acme_app /密码:
火花。密码{{秘密/ acme-app /密码}}
有关更多信息,请参见语法引用火花配置中的秘密财产或环境变量。
环境变量
您可以配置自定义环境变量,您可以访问init脚本在一个集群上运行。砖还提供了预定义的环境变量在init脚本,您可以使用。你不能覆盖这些预定义的环境变量。
在集群配置页面,单击高级选项切换。
单击火花选项卡。
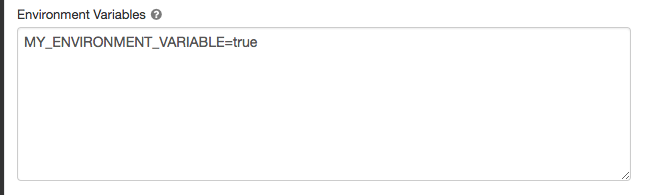
设置环境变量环境变量字段。

集群日志交付
当您创建一个集群时,您可以指定一个位置提供的日志引发司机节点,工作节点,和事件。日志是每5分钟发送到您所选择的目的地。终止一个集群时,砖保证交付的所有日志生成到集群是终止。
日志的目的地取决于集群ID。如果指定的目的地dbfs: / cluster-log-delivery、集群日志0630 - 191345 leap375交付给dbfs: / cluster-log-delivery / 0630 - 191345 leap375。
配置日志交付地点:
在集群配置页面,单击高级选项切换。
单击日志记录选项卡。
选择一个目的地类型。
进入集群日志路径。
日志路径必须是DBFS开头的路径
dbfs: /。
请注意
这个功能也可以在REST API。看到集群API。